|
||||||||||||
|
Download spreadsheet with data for these four phenomena (Note: to come back directly to this page after clicking on a link to do a query, click on RETURN in upper right-hand corner) |
|
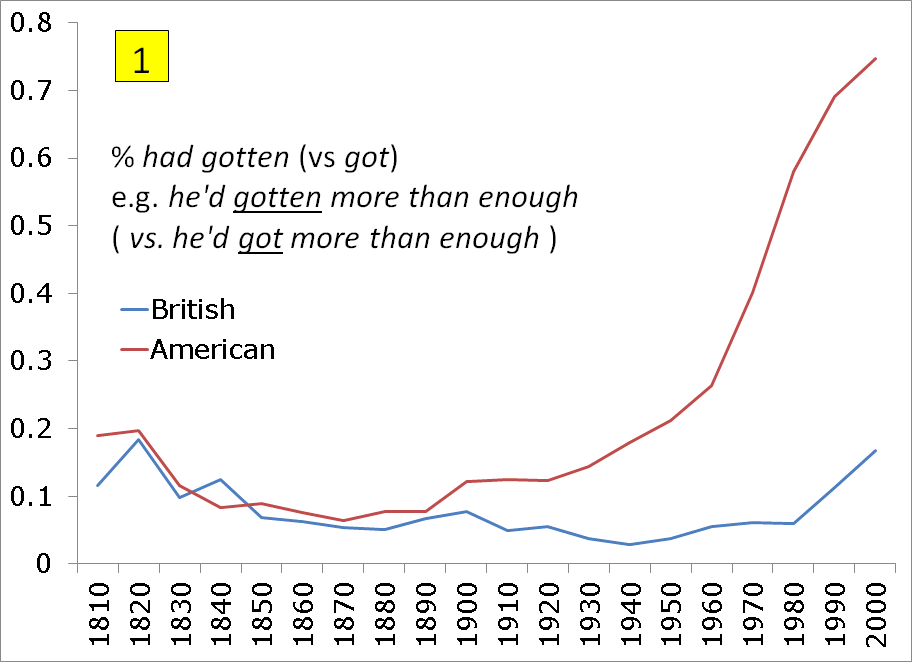 |
Chart #1 to the left shows that gotten (vs got: he'd gotten more than enough) is much more common in American English (red line) than in British English. It is interesting that the two dialects were roughly similar until about 1900, when they diverged. The Google Books data also agrees with the COHA data (see spreadsheet), which shows the largest increase from the 1920s-1930s. The data also suggests that British English is moving slightly towards the "American" gotten in the last 20 years, but this is much less likely. In the British National Corpus, gotten is still at only about 1.5% of all tokens (got, gotten), not the 17% shown in Google Books-- British for the 2000s (see spreadsheet for BNC data). This suggests that with this Google Books data, some American books (with gotten) were mistakenly categorized as British. (On the other hand, the BNC is now 20-30 years out of date, so the 5.9% gotten in Google Books -- British in the 1980s is closer to the 1.5% in the BNC from the 1980s-1993. Perhaps there has been an increase in gotten in British English since the early 1990s, but with no large, balanced corpus of contemporary British English, we'll never know.) Data: |
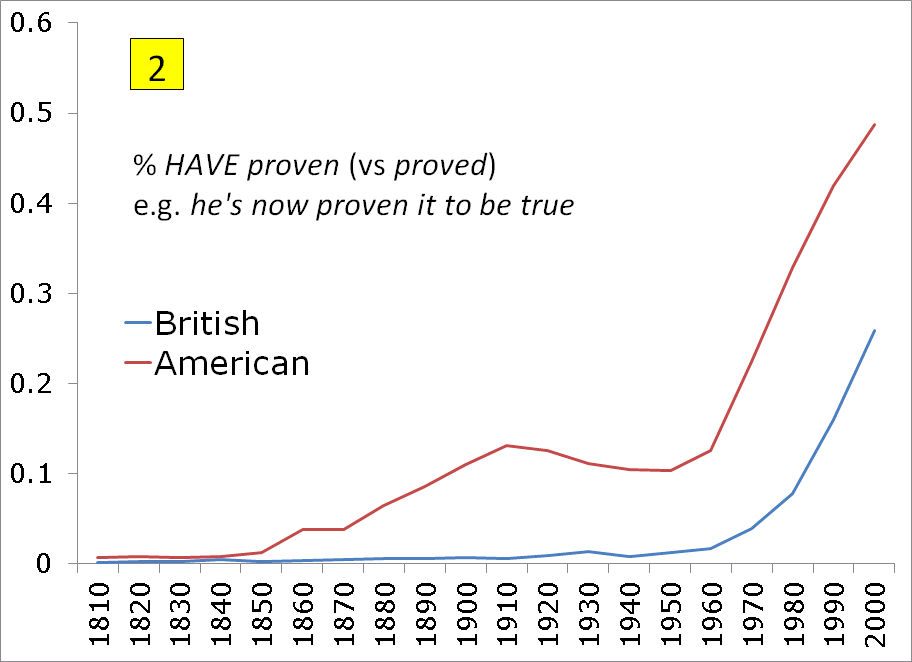 |
British English strongly prefers HAVE + proved, whereas American English allows both proved and proven (see discussion). Chart #2 does show a greater preference for proven in American English. It also suggests that proven has increased since about the 1930s-1950s, which agrees with the COHA data (see spreadsheet)). As with the data for got/gotten (#1 above), we are again faced with a problem for British English for the 1980s-2000s. Google Books shows that proven is increasing, but 25% proven for the 2000s seems unlikely. In the BNC, it is about 5% (see spreadsheet), and Google Books shows about 8% for the same period -- the 1980s. But without an updated British corpus since the early 1990s, it's impossible to know exactly what's going on. Data: |
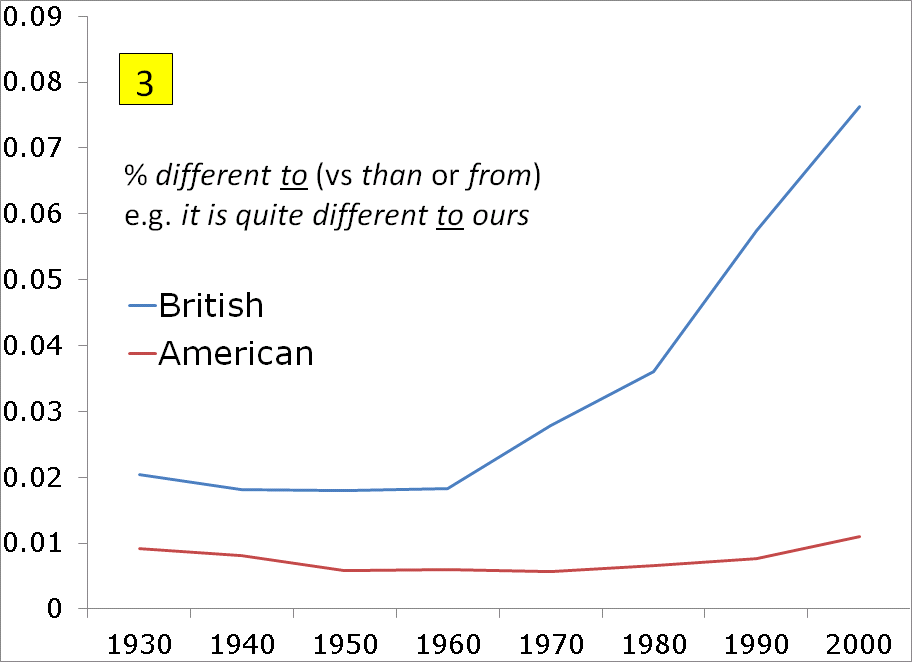 |
American English allows different from and different than, while British English rarely allows than, but it does allow to (it is quite different to ours). (In all of these examples, we limited the search to [be] different to the (e.g. it is different to the one we have), to exclude spurious cases like everyone has something different to offer.) The Google Books data does show that to is much more common in British English (blue line). But the 3.7% to in Google Books -- British for the 1980s seems quite a bit lower than the 12.7% to in the BNC (see spreadsheet). One possible explanation for this is that Google Books has categorized some American books (without to) as British, thus providing too low of a figure for British. |
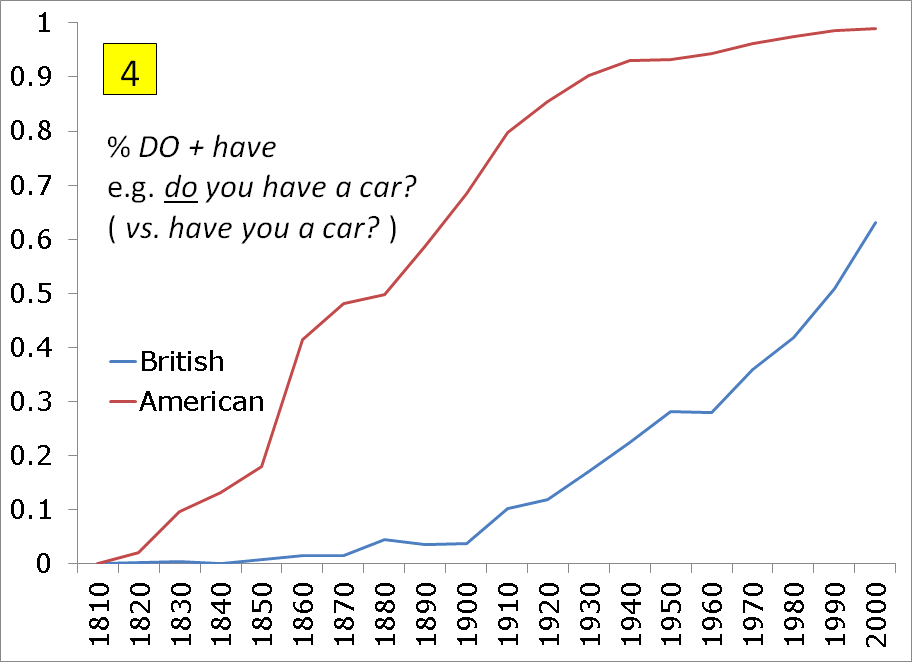 |
While American English used to treat "possessive have" (I have a car) as an auxiliary, it is now treated as a main verb and it takes "do support" in negation and questions (e.g. do you have a car?) In British English, however, possessive have can still be considered an auxiliary verb, and thus there is inversion and no do in questions (e.g. have you a car, cf. have you seen him?). Chart #4 shows this very nicely. It shows that American English began to diverge from British English in the early 1800s, and that there has been a constant and sustained increase in +do since then, which agrees nicely with the COHA data (see spreadsheet). In the BNC (see spreadsheet), +do is very much the norm in spoken, informal British English -- at 90% or more. The lower 40-50% +do in Google Books -- British may be due to the fact that there are more formal books in Google Books than in the BNC, or at least less books with second-person questions like "do you have a". |
|
In summary, some data (like that shown in the four phenomena above) suggest that Google Books has a fairly good job of separating books into American and British. But there is still a lot of "messiness" in the data -- perhaps as much as 10-20%. While it might be fine to use Google Books as a "starting point" to look at differences in British and American English, it probably makes sense to use a more accurate corpus for fine-grained studies. For American English, we do have such a corpus in the 400 million word Corpus of Historical American English (COHA). Unfortunately, there is currently no such large, accurate corpus of historical British English. |
|
Mark Davies
Professor, Corpus Linguistics/p>