|
| Resource | Size (# words) | When released | Wide range of searches | |
| 1 | Corpus of Historical American English (COHA) | 475 million | 2010 | Yes |
| 2 | Google Books (Standard): American English | 155 billion | 2010 | No |
| 3 | Google Books (E-C/Advanced): American English | 155 billion | 2011 | Yes |
Before getting too far into this comparison, we should first acknowledge the great job that the Google Books people have done in scanning and making available millions of books. This is an absolutely Herculean task, and we are very grateful that Google has generously made all of this data available to researchers like us to adapt it for their own purposes. Just because we have "issues" with the simplistic Google Books interface doesn't mean that we don't really appreciate everything else that Google Books has done in creating the underlying data.
As we will see, the regular Google Books resource (#2) is a huge "corpus", but is extremely limited in terms of the searches that it allows. COHA is much smaller (although still 100 times as large as nearly all other corpora of historical English), but it allows for an extremely wide range of searches. The E-C/Advanced version of Google Books (released in 2011) is a hybrid -- it has the same "data" as the regular Google Books, but it allows for many of the same searches as COHA.
1. Exact words and phrases (POSSIBLE / NOT POSSIBLE)
Note: click on [RETURN] in the upper right-hand corner after doing a search, to return to this page
| COHA | Google Books: Standard | Google Books: E-C/Advanced | ||
| 1 | Individual words and phrases | |||
| 2 | Compare frequency |
he sneaked he snuck BOTH (TABLE) |
he sneaked he snuck (no data to copy and compare) |
he
sneaked he snuck BOTH (TABLE) |
| 3 | Get total frequency |
end up doing [end] up doing [end] up VERB-ing |
end up paying ended up doing (individual searches; can't combine) |
end up
doing [end] up doing [end] up VERB-ing |
1. All three resources -- Google Books (both versions) and COHA -- give nearly the same results for these searches. The 475 million words in COHA is probably sufficient for nearly all searches of individual words and phrases.
2. With Google Books (Standard), there is no actual data that can be copied to another application for analysis (it's just a picture of the frequency), and no indication of actual frequency (absolute number of occurrences).
3. With Google Books (Standard), you can't get the total frequency of related phrases (e.g. end up doing, all forms of end + up + doing, or all forms of end + up + all verbs). (See #7 below, for more details). Even if you could do one search to get many forms at once (which you can't), you still can't combine them, because they are nothing but pictures.
2. Related words and cultural insights
| COHA | Google Books: Standard | Google Books: E-C/Advanced | ||
| 1 | Search all forms (wildcards) |
*heart* *ism* |
||
| 2 | Compare by period |
*heart* *ism* |
NO |
*heart* *ism |
1. With Google Books, you're limited to looking at individual words and phrases; neither of the searches above will work. With COHA and Google Books (E-C/Advanced), however, you can do much more interesting and useful searches, like finding all words with the root *heart* or the suffix *ism.
2. Notice how a comparison of many related words gives great insights into cultural and historical changes in American English. In the case of *ism, for example, we see which words are most frequent in different decades (patriotism, communism, heroism, terrorism, skepticism, racism, etc).
3. Searching for concepts, not just exact words and phrases
| COHA | Google Books: Standard | Google Books: E-C/Advanced | |
| Use synonyms |
"beautiful" "beautiful" woman "clever" "clever" person "clean" the NOUN |
No synonyms |
"beautiful" "beautiful" woman "clever" "clever" person "clean" the NOUN |
With COHA and Google Books (E-C/Advanced), you can use built-in synonyms to search for the frequency of "concepts" like "beautiful", "beautiful" woman, "clever", "clever" person , or "clean" the NOUN by decade. Or (in COHA) you can use customized lists that you've created via the web interface (e.g. words referring to the body) to search for a semantically-oriented search like "briefly touch someone" (stroking her hair, rubbed his chin, patted her shoulder, etc) (will be available soon in Google Books [E-C/Advanced]).
The point is that with COHA and (to a somewhat lesser extent) Google Books (E-C/Advanced), you can search for concepts and ideas. With Google Books (Standard) you're just looking at exact words or phrases.
4. Changes in meaning (semantic change)
| COHA | Google Books: Standard | Google Books: E-C/Advanced | |
| Use collocates (nearby words) | words "near" gay |
No collocates (nearby words) |
words "near" gay |
| Compare by period | YES | NO | YES |
How can you tell if a word has changed meaning? You could look at thousands of occurrences in different periods and see if it looks like it's being used in a new way. But this is really time consuming. An easier and quicker way is to find the collocates (nearby words) for a word, and see if the collocates change over time. If so, it may be because the word that we're interested in has changed. (By analogy, changes in the people you "hang out with" on a daily basis may indicate changes in your life -- graduation, marriage, children, etc.)
For example, we all know that the word gay has changed meaning in the last 50-60 years. With COHA (and also Google Books (E-C/Advanced), to a lesser extent) we can easily find the collocates of gay decade by decade, and we can also directly compare the collocates in different sets of decades (e.g. gay in 1830s-1910s vs 1970-2000s). We see that whereas gay was used previously with brilliant, attractive, jolly, and joking, it now occurs with heterosexual, sexes, groups, and bisexual. Hence the changing collocates (the nearby words) signal changes in the meaning of the word itself.
To use collocates with Google Books (Standard), you would have to manually download thousands or millions of hits to your computer, and then use another program to look for and categorize the collocates. This would all be quite cumbersome and time-consuming. With COHA and Google Books (E-C/Advanced), it can easily be done in 2-3 seconds.
5. Collocates and cultural shifts
| COHA | Google Books: Standard | Google Books: E-C/Advanced | |
|
Compare collocates in |
fast art women music food |
NO collocates |
fast art women music food |
As discussed in the section above, collocates can provide great insight into cultural and societal shifts. (Note that COHA does collocates much better than Google Books (E-C/Advanced), due to the underlying architecture.) Compare the following (from COHA), and see if you can tell what the collocates tell us about changing views and values:
| Words
near (click above to see) |
Time period 1: collocates (left) | Time period 2: collocates (right) |
| art | 1830s-1910s: noble, classic, Grecian | 1960s-2000: abstract, Asian, African, commercial |
| fast | 1850s-1910s: mail, train, horses, steamers | 1960s-2000s: food, track, lane, buck |
| women | 1930s-1950s: ridiculous, plump, loveliest, restless, agreeable | 1960s-1980s: battered, militant, college-educated, liberated |
| music | 1850s-1910s: delightful, exquisite, sweeter, tender | 1970s-2000s: Western, Black, electronic, recorded |
| food | 1850s-1910s: spiritual, insufficient, unwholesome, mental | 1970s-2000s: fast, Chinese, Mexican, organic |
Google Books (Standard) and Culturomics can't look at cultural change in this way. All it can do is look at charts of the frequency of art (little change), fast (no change), women (increasing), music (little change, 1900s), or food (little change, 1900s) which aren't overly insightful. In these cases, collocates are needed to look at cultural shifts, and only COHA and Google Books (E-C/Advanced) are able to do collocates.
6. Looking at the function of words
| COHA | Google Books: Standard | Google Books: E-C/Advanced | |
| Word by function |
swell (ADJ) for (CONJ) pretty (ADV) |
Can't search by part of speech (see note below) swell for pretty |
[a] + swell + [NOUN] for + [if] pretty + [ADJ] |
We might want to limit our searches by part of speech, such as:
-
swell as adjective (we had a swell time) but not verb (her leg will swell up)
-
for as conjunction (... for had they known...) but not preposition (they slept for ten hours)
-
pretty as adverb followed by an adjective (she's pretty tired right now) but not an adjective itself (she's a pretty girl)
COHA can generally limit the search correctly (click above to see any of these). This is because COHA is a real linguistic corpus, and each of the 475 million words in the corpus is "tagged" by context for part of speech. Google Books (E-C/Advanced) has a bit more of a problem, but with enough context it usually comes close.
Google Books (Standard) says that it can search by part of speech (see "Part of Speech tags" here). But there is absolutely no way to test this, because once you search by part of speech, then all of the links to the "Word in Context" display are disabled. (For example, search for "swell _NOUN"), and notice that the links below the chart (which are available with a search like swell -- see "Search in Google Books" at the bottom of the page) are gone. You simply have to accept "on faith" that Google tagged these correctly, and there is no way to verify this.
7. Grammatical change (syntax)
| COHA | Google Books: Standard | Google Books: E-C/Advanced |
|
C = CHART, T = TABLE so ADJ as to VERB (C/T) [end] up VERB-ing (C/T) VERB one's way PREP (C/T) VERB PRON into VERB-ing (C/T) |
No part of speech, so no syntactic searches |
C = CHART, T
= TABLE so ADJ as to VERB (C/T) [end] up VERB-ing (C/T) VERB one's way PREP (C/T) VERB PRON into VERB-ing (C/T) |
So if Google Books doesn't know about part of speech tags or variant forms of a word (and see #6 above for problems with verifying what it claims it knows), then how can it look at change in grammar? For example, suppose you want to look for the now "old-fashioned" construction [ so ADJ as to VERB ] (e.g. so good as to show me, so daring as to rouse them). With Google Books, we would have to search for [ so x 1000s of adjectives x as to x 1000s of verbs = millions of individual searches]. Even if this were possible (which it's not), it would take months or years. With COHA and with Google Books (E-C/Advanced), we can do this in less than two seconds (see links above).
Or what about the construction [ VERB PRONOUN into VERB-ing ] (he talked them into going, Sue forced them into revealing their secret), which is increasing over time. The only part of this phrase that Google Books (Standard) could understand is the single word into, and it's not going to do any good to look just for that one single word. With COHA and Google Books (E-C/Advanced), on the other hand, we can search for all matching strings at one time (see links above) -- in about two seconds.
COHA and Google Books (E-C/Advanced) can quickly and easily look at grammatical change, but this is often difficult or impossible with Google Books (Standard).
Language change often "spreads" through genres, such as from informal to more formal speech and writing. COHA allows users to map out the changes by genre (fiction, magazine, newspaper, and non-fiction / academic books). Examples are the two changes shown below -- the decrease in whom, and the increase in end up.
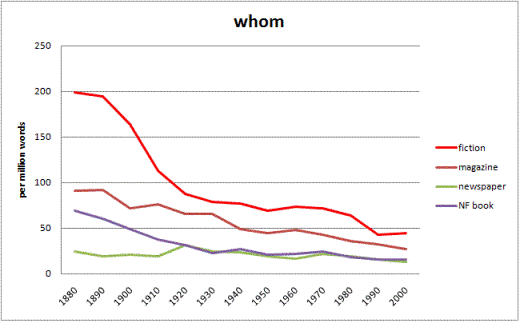
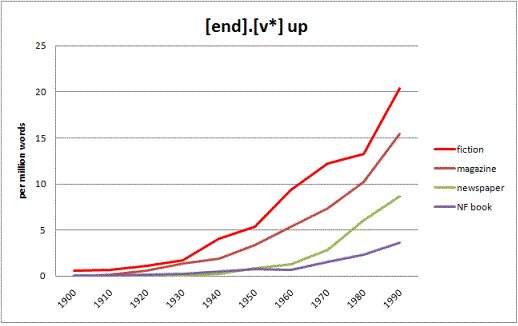
Google Books (Standard and Advanced) is unaware of genre, and is unable to show how language change spreads from one genre to another.
The Google Books (Standard) interface is "cool", "simple", and "fast", which is what has made Google so popular over the years. But all it can do is find the frequency of an exact word or an exact phrase over time, and in most cases the 475 million word COHA corpus usually gives about the same results for these searches.
On the other hand, both COHA and Google Books (E-C/Advanced) are able to look at many changes that can't be studied (easily, or at all) with Google Books:
-
lexis (words), via mass comparison between historical periods
-
morphology (word formation), via wildcards
-
syntax (grammar) via the part of speech "tagged" corpus, and
-
semantics (word meaning), via collocates, synonyms, and customized lists
Finally, we appreciate the attempt that Google Books (Standard) and Culturomics have made to produce a resource that can be used to look at cultural changes in the US, and they do yield a lot of interesting data. As we've discussed, however, COHA and Google Books (E-C/Advanced) allows more powerful searches (with collocates, synonyms, and comparing all words in different historical periods), which (in our estimation) often produces much more insightful analyses for these cultural and societal shifts.
Mark Davies
Professor, Corpus Linguistics
Brigham Young University
Provo, Utah, USA