In May 2016 we also released a new version of the corpora from English-Corpora.org. The following
are the major changes to the corpus architecture and interface. (Problems?...)
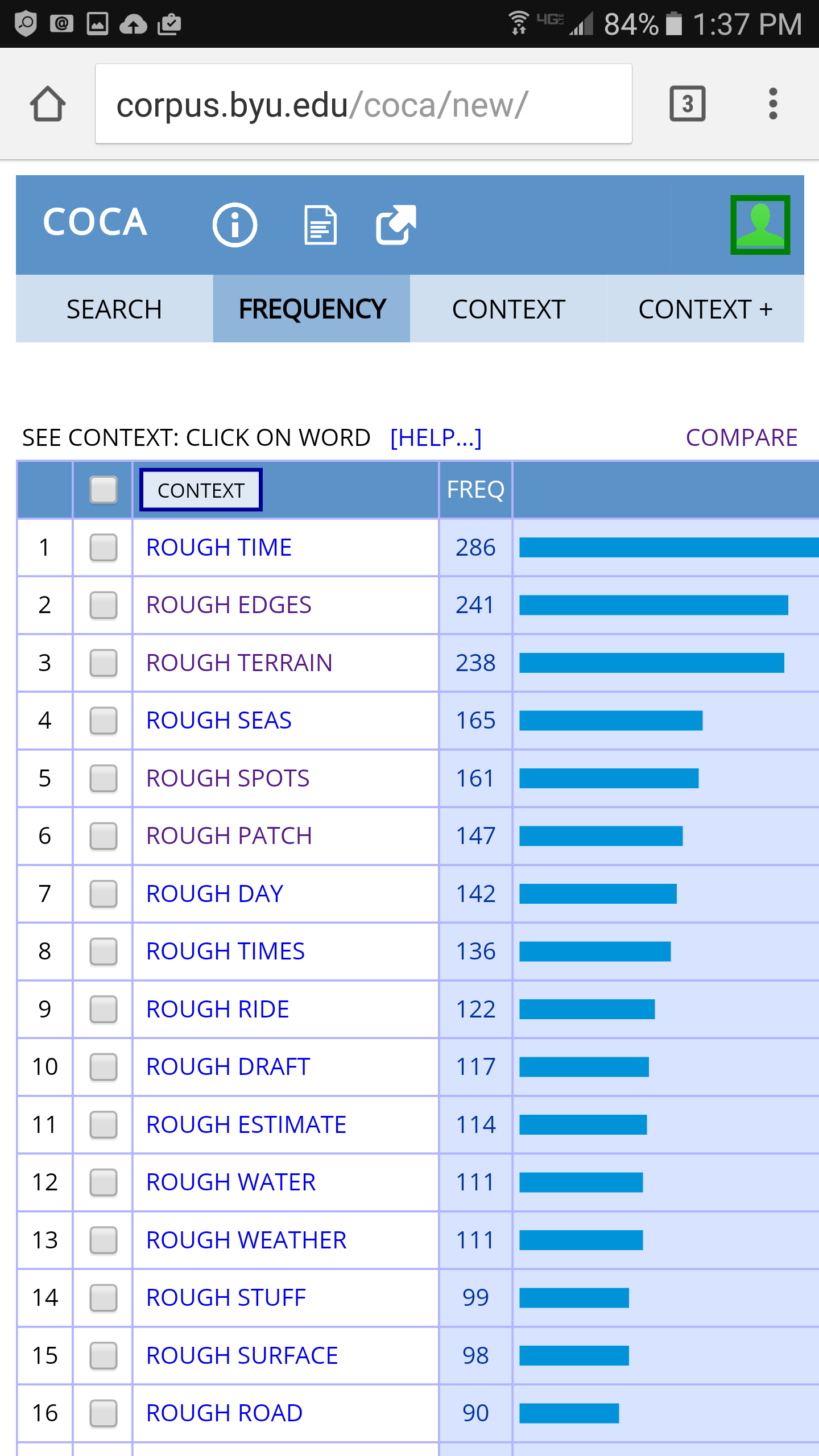
1. More mobile-friendly
The previous
interface had lots of frames. These worked well
on laptop and and desktop computers, but not very well with mobile phones or
tablets. The new interface is designed from the ground up to work on screens of
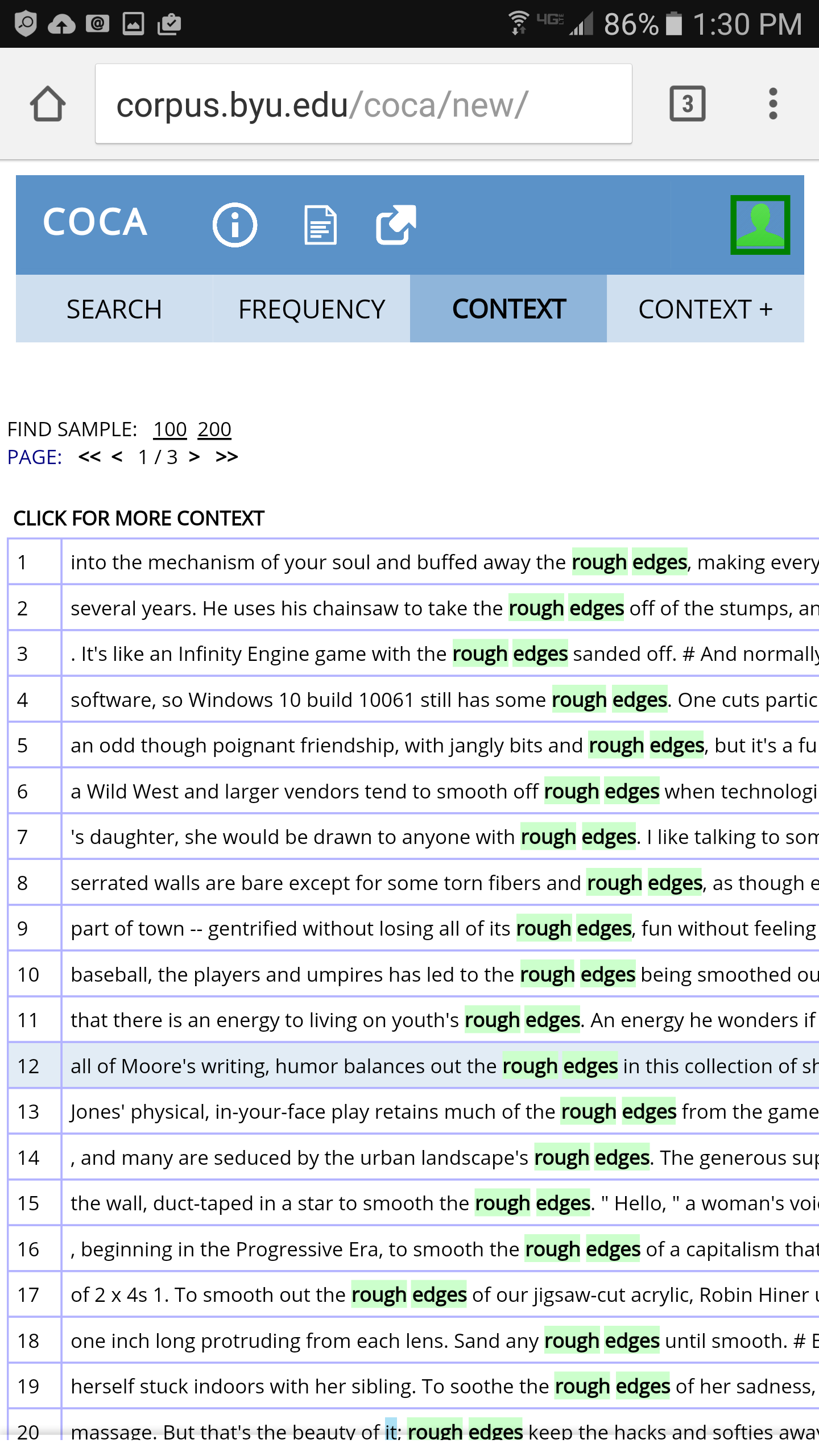
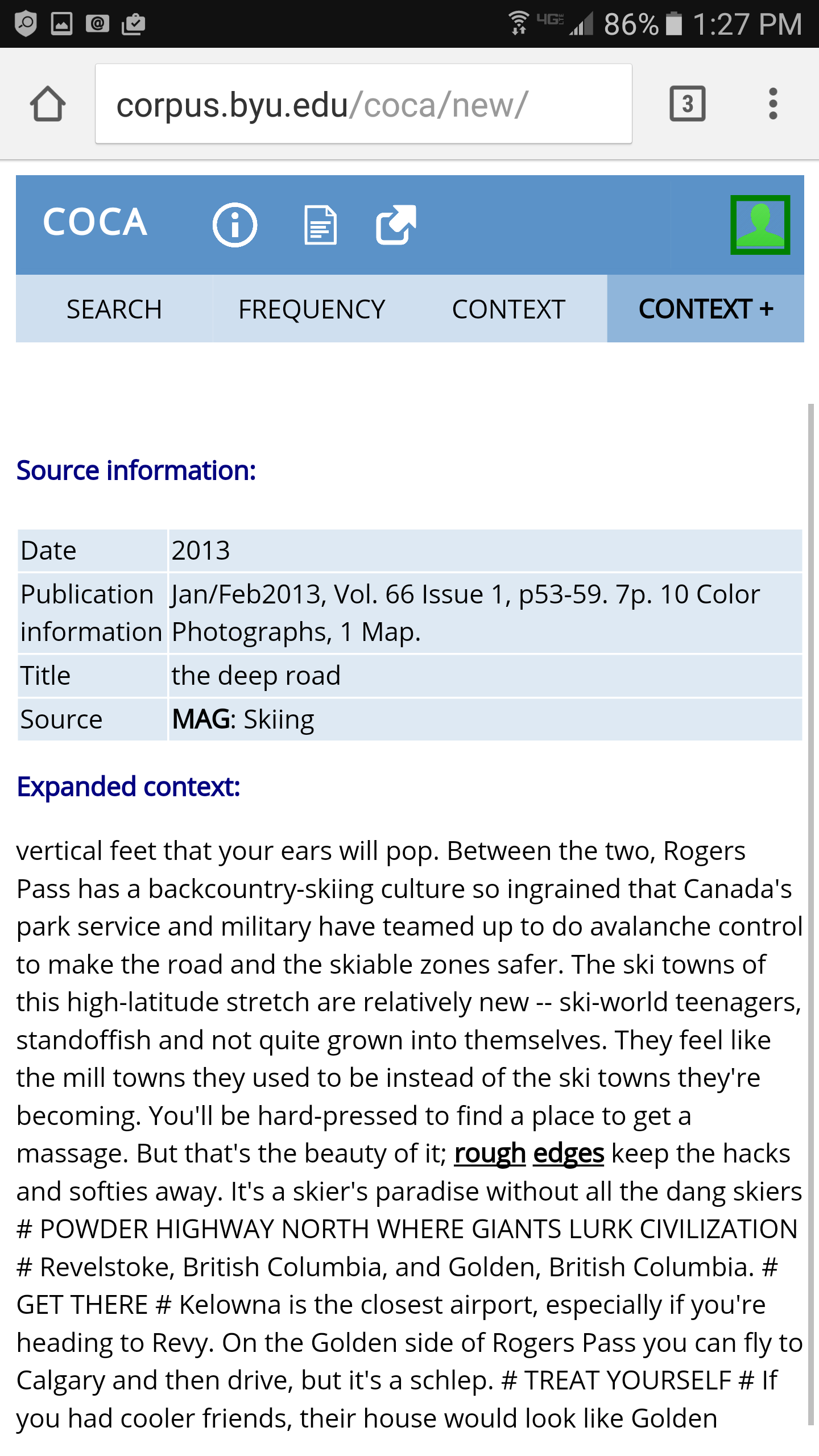
any size. The following are some screenshots from a mobile phone for (left to right) the search
interface, results display, Keyword in Context display (KWIC), and expanded KWIC.
The interface looks even better on a device with a larger screen, but the bottom line is that the
corpora now look and work fine, no matter what device you're using. (Note: the
older interface will still be online as well, at least for the foreseeable
future.)
2. Cleaner, more simple interface
The search form in the previous interface was a bit
overwhelming (below, left). The newer interface is much cleaner and simple to
use (below, right). All of the previous functionality is still there -- the
ability to limit by and compare sections of the corpus, deciding how to sort the
data, etc -- but now those form elements only appear when you need them.
| Previous interface
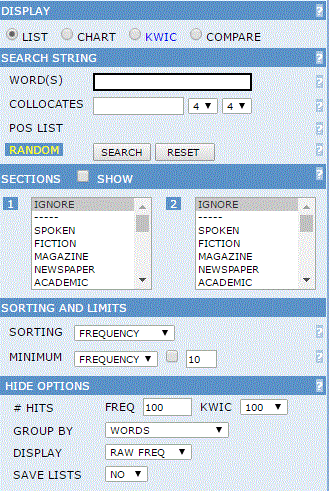
|
New: simple list view
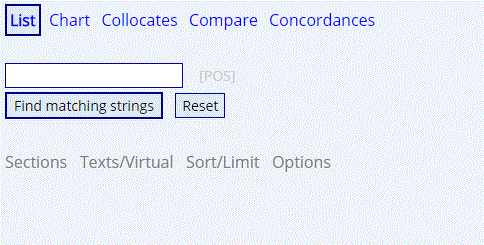
New: collocates view

|
3. More helpful help files
Context-sensitive help files now appear whenever
you click on a form element -- list, collocates, compare words, sections,
virtual corpora, etc. And there are sample searches in each of these files,
which you can modify to make your own searches.


4. Simpler, more intuitive search syntax
Some search syntaxes are (in
our view) unnecessarily complex, like the CQP syntax on the left. The previous
search syntax had a much simpler syntax, but there were still too many
square brackets, full stops, asterisks, etc (no fun to type these on a mobile
phone keyboard). We have now simplified the search syntax even more, as is shown
on the right. But while they're learning the newer, simpler syntax, people can
still use any combination of the older and newer syntax.
(For more information, including the new
part of speech codes, click on LIST in the search form of a corpus, and then
Part of Speech)
| Type of search |
CQP syntax |
Previous search syntax |
New syntax |
Example |
| Word |
[word = "nooks"] |
nooks |
nooks |
nooks and crannies |
| Lemma (forms of word) |
[lemma = "decide"] |
[decide] |
DECIDE |
DECIDE that it |
| Part of speech |
[tag = "NN."] |
[nn*] |
NOUN |
fast NOUN |
| Synonyms |
Not possible |
[=soft] |
=soft |
soft, smooth, quiet |
| Customized word lists |
Not possible |
[emailAddress@clothes] |
@clothes |
dress, shoe, sock |
| Combinations of preceding |
[lemma = "end" & pos = "VV."] |
[end].[v*] |
END_v |
end, ends, ended, ending |
| Combinations of preceding |
[lemma = "eat"] [tag = "NN."] |
[eat] * [nn*] |
EAT * NOUN |
ate the bananas, eat some cake |
| Combinations of preceding |
Not possible |
[[emailAddress@clothes]] |
@CLOTHES |
dress, dresses, shoe, shoes |
| Combinations of preceding |
Not possible |
[[=clean]].[v*] |
=CLEAN_v |
cleans, scoured, washing |
| Combinations of preceding |
Not possible |
[wear] * [=nice]
[email@clothes] |
WEAR * =nice @CLOTHES |
wore some good-looking pants |
5. Virtual corpora
In early 2015
we added the ability
to create "virtual corpora" for the
Wikipedia corpus. In just a few seconds, users could create a virtual corpus
of texts related to biology, Buddhism, investments, basketball -- or thousands
of other topics. They could then modify these corpora -- adding, deleting, or
moving texts. They could limit their searches to a particular virtual corpus
(e.g. collocates of stress in psychology or engineering), and compare the
frequency of a word or phrase in their different virtual corpora. And best of
all, they could create keyword lists for any of the virtual corpora -- in just a
few seconds.
We have now added the "virtual corpus"
functionality to all of the corpora from English-Corpora.org, which allows you to quickly and easily
create and use virtual corpora from any of the texts in these corpora. For
example, you could create a virtual corpus of texts from
Cosmopolitan or
Astronomy magazines (COCA), newspaper articles dealing with the New Deal from
1932-1938 (COHA), web pages from a particular website dealing with cricket in
the UK (GloWbE), speeches by Winston Churchill from 1939 to 1945 that
mention Germany (Hansard), or newspaper articles from September 2015 dealing with the
European refugee crisis (NOW). Click on VIRTUAL/TEXTS in any of the corpora for
much more detail and some great examples of these virtual corpora.
In May 2016 we also released the
following new corpora:
NOW corpus ("News
On the Web") This 3 billion word corpus is like a "GloWbE
monitor corpus" (allowing you to look at changes over time), and it will never be more than 24 hours out of date.
We have
created a
series of scripts that add about four million words of data (from the same twenty
countries as GloWbE) every night (so ~130 million words a month / 1.5
billion words a year). The scripts run automatically from 10 PM - 1 AM --
getting the URLs from Google News;
downloading the 7,000-8,000 web pages with
HTTrack; cleaning them up
with JusText
(to remove boilerplate material); tagging and lemmatizing with
CLAWS 7; and then
integrating them into our existing relational database
architecture.
So when people
search the NOW corpus, the data will
be current as of no more than 24 hours ago, which should be useful for
research that would benefit from up-to-date corpora (i.e. no more stale examples
from corpora that only contain texts from the 1980s or 1990s -- a full generation
ago).
The interface also
allows users to find keywords and key phrases for any date or range of dates, and
to quickly and easily find the "most recent 100" tokens of any word, phrase, or construction. Finally,
in Summer 2016 we will also make available by subscription the ~130 million words of
cleaned texts every month, similar in format to the other
full-text data.
Corpus of Web Genres.
Douglas Biber,
Jesse Egbert, and
Mark Davies received a grant
from the US National Science Foundation to create "A
Linguistic Taxonomy of English Web Registers", and this corpus is the
fruit of that research (see also articles
1, 2,
and our 2017 book on "web registers" from Cambridge University Press). The
corpus contains more than 50 million words of text from the web, and it is the first large web-based corpus that is so carefully categorized into so
many different registers. This is quite different
from other very large corpora that simply present huge amounts of data from web
pages as giant "blobs", with no real attempt to categorize them into linguistically distinct
registers.
We hope that these new features and corpora will be
of benefit to you in your teaching, learning, and research.
|

{kind=link}