The
Corpus of Historical American English and small corpora (Brown+, ARCHER, etc)
There are a number of other corpora of historical English for the
1800s-1900s. Some of the better-known ones are the
BROWN family
of corpora,
ARCHER,
CONCE,
and
DCPSE. The data from these corpora has resulted in many insightful studies.
Like these other corpora, COHA is well-balanced in
terms of genres and the corpus has roughly the
same genre balance from decade to decade. As a result, it is not surprising that -- for the
constructions where there is enough data in small corpora -- the COHA data is quite similar.
This should be reassuring to those who are used to the more
"established" corpora.
To give a few examples, the following table shows data from COHA, TIME,
and COCA for some constructions that have been researched in recent
studies using the
BROWN family
of corpora (hereafter BROWN+; 4 million words 1961 / 1991; Brown, LOB, FROWN, FLOB)
| Conclusions from
BROWN+ |
475 million words
1820-2019 |
100 million words
1920s-2000s |
1,000 million words
1990-2019 |
| decrease in
which as a relative pronoun |
COHA |
TIME |
COCA |
| decrease of
upon |
COHA |
TIME |
COCA |
| decrease of
for as a conjunction |
COHA |
TIME |
COCA |
|
increase in
semi-modals like need to |
COHA |
TIME |
COCA |
| decrease with
modals like must |
COHA |
TIME |
COCA |
decrease in progressive
passive
(last 30-40 years) |
COHA |
TIME |
COCA |
| decrease (overall) with
the passive |
COHA |
TIME |
COCA |
| increase in the
get
passive |
COHA |
TIME |
COCA |
Note that -- in order to
simplify this web page -- these links are just for one-step queries. For some of
the phenomena, we'd need to run more than one query and adjust the
frequencies. For example, with that/which as relative pronouns (the
argument that/which he makes), we would run a second query (using
customized wordlists) to find
noun complements (e.g. the fact that they won't be here) and then
subtract those from the relative pronoun counts.
There are two important differences between COHA and these other corpora,
however. The first is that COHA
has an architecture and interface that
allow researchers to look at many
kinds of phenomena that would be difficult or impossible to
study otherwise -- in terms of morphological, syntactic, semantic, and
lexical change.
The second main difference between COHA and corpora like
ARCHER,
CONCE,
DCPSE, and the
BROWN
family of corpora relates to
size. COHA is about 100-475 times as large as the four
corpora listed above. In addition, the COHA texts provide data that are
continuous, meaning that they sample the language every single year
from 1810-2009, rather than just every 30 years or so. (For example,
there are about 2 million words each year
from the 1880s-2000s). Because of its size and continuous nature,
COHA provides robust, granular data that is impossible with the other corpora.
Because there is so much continuous data, we can look at specific
changes in incredible detail, and then compare those changes to
others that are occurring at about the same time, to see
how the changes are related. Let's look at a quick example.
The following chart
shows the shift from to-V (he started to sing) to V-ing (he
started singing) with a number of verbs during the past 200
years.
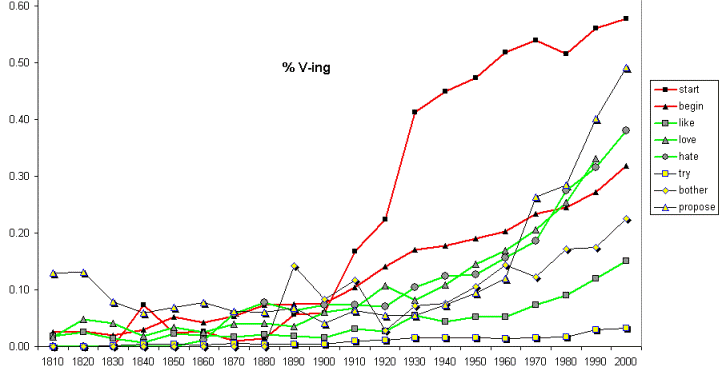
Even though the chart has a lot of lines, notice how the first
significant shift towards V-ing seems to occur with start in
about 1900-1920s, followed by the less frequent but semantically-related
verb begin (the red lines). Then in
about the mid-1900s, there is an increase with the related "emotion" verbs
like, love, and hate (the green lines), with the
biggest increases with the emotionally strongest verbs -- love
and hate.
Here's the point, though. The following is the data for hate (e.g.
I hate to write papers > I hate writing papers).
| |
1860s |
1870s |
1880s |
1890s |
1900s |
1910s |
1920s |
1930s |
1940s |
1950s |
1960s |
1970s |
1980s |
1990s |
2000s |
|
to_v |
86
|
129
|
156
|
178
|
281
|
383
|
437
|
419
|
346
|
372
|
323
|
338
|
288
|
300
|
400
|
|
V-ing |
1
|
8
|
13
|
12
|
22
|
30
|
33
|
49
|
49
|
54
|
60
|
77
|
109
|
138
|
245
|
|
% V-ing |
0.01
|
0.06
|
0.08
|
0.06
|
0.07
|
0.07
|
0.07
|
0.10
|
0.12
|
0.13
|
0.16
|
0.19
|
0.27
|
0.32
|
0.38
|
Imagine that instead of 475 million words (the size for COHA), we had a
corpus 1/100th or 1/200th that size -- or in other words, the size of
ARCHER, CONCE, the BROWN family, etc. Rather than 300-400
tokens in a given cell in the table above, we'd have 1 or 2. With such
sparse data, we couldn't really map out the shifts with any given
verb or see the relationship between the different verbs.
The example above deals with syntactic change. We could repeat this
example with any number of other examples in syntax or in other
areas dealing with language change. Here's just a few:
-
(lexical)
verbs with
up
in the 1880s-1920s (left) compared to the 1960s-2000s (right)
-
(morphological)
-able adjectives
1810s-1910s (left) compared to 1920s-2000s (right)
-
(semantic)
collocates of gay
in the 1840s-1910s (left) compared to the 1970s-2000s (right)
In each case, the number of
tokens with a given word or collocate occurs just 20-60 times, even in
the 475 million word corpus. In a small 2-4 million word corpus, it
would occur at about 1/100th or 1/200th this rate -- or in other words,
maybe one or two tokens. That would not be enough to look at any of
these -- or any similar -- changes.
With a small 2-4 million
word corpus, we are limited to looking at
just high frequency phenomena -- like modals, passives, perfects, progressives,
prepositions, conjunctions, and relative pronouns.
There has been some great research done on these
topics over the years, by some of the best researchers in the field of
Late Modern English. But after 20-30 years of research on this handful
of phenomena, we would suggest that it's time to move on
to a
wider range of phenomena. The 475 million word Corpus of Historical
American English is arguably the only publicly-available, structured corpus of
historical English that allows us to do so.
|
