Chart searches (search
form,
corpora used,
corrections,
+/- sections)
Chart searches (search
form,
corpora used,
corrections,
+/- sections)
 |
Note: click on any link
on this page to see the corpus data, and then
click on the "BACK" image (see left) at the top of the page to come back to
this page. Or right click on the link and then "Open link in new tab" (in
Chrome; similar in other browsers), and then close that tab after
viewing the corpus data. |
In most cases, the examples in
these linked pages comes from the Corpus of Contemporary American English
( COCA), since it is the most widely used of the corpora from English-Corpora.org
(and probably the most widely-used online corpus anywhere).
A number of examples also come from
COHA (historical),
GloWbE (dialects), and
NOW (very large and recent). But all of the information in these help files should
be applicable to any of the 17 corpora at English-Corpora.org.
(close)
Please note that these pages were recently released (in September
2024), and there are probably still some errors, since English-Corpora.org has
been created and is run by just one person. If you find anything that needs to be corrected, please
email us. Thanks.
(close)
Chart searches show the overall frequency of a word, phrase, or
grammatical construction in the corpus. A LIST search will show the
frequency of each matching string, whereas a CHART search shows the
overall frequency of all matching strings, in each "section" of the corpus. These sections will vary from corpus to
corpus -- for example, genres and time period (five year blocks) in
COCA, countries
and decades in the TV
or Movies
corpora, years in NOW,
countries in
GloWbE, genres in the
BNC, or decades
in COHA,
TIME,
Hansard, or
EEBO. For
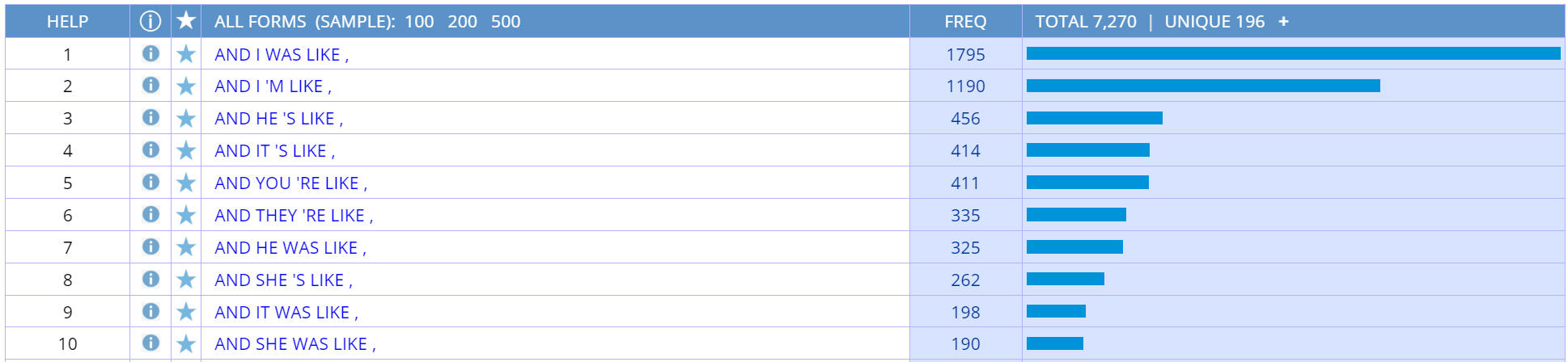
example, compare the
CHART and
LIST searches for the "like
construction" (and I was like, and she's like ,) in
COCA. Notice that it is much more frequent in informal genres like
Spoken and TV/Movies, and that it is very much increasing over time.
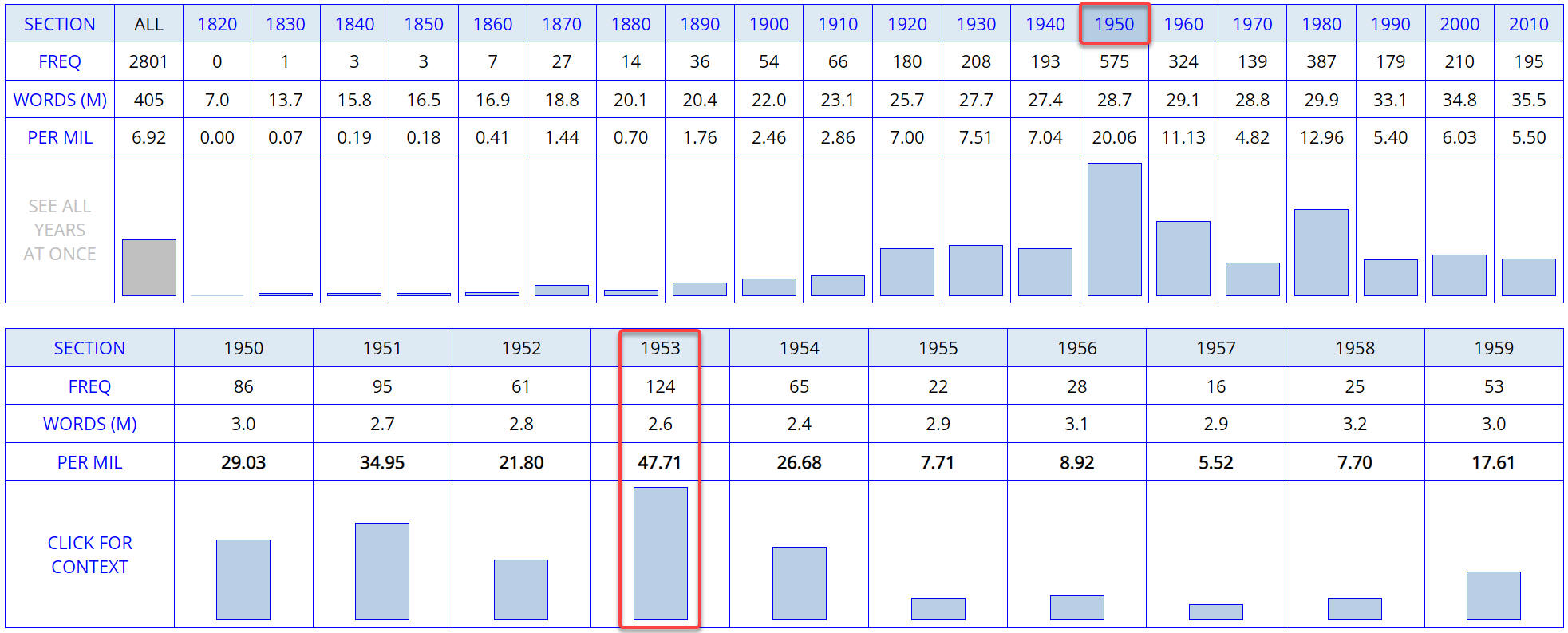
| In most of the corpora, it is possible to
"drill down" even further to see the frequency in smaller "sections" of
the corpus. For example, the chart to the right shows the frequency of
reds
(a derogatory term for Communists) in the
COHA Corpus (475
million words, 1820s-2010s), and then by year within the decade of the
1950s (note the highest frequency in 1953, at the height of the
McCarthy
hearings in the US Senate): |
 |
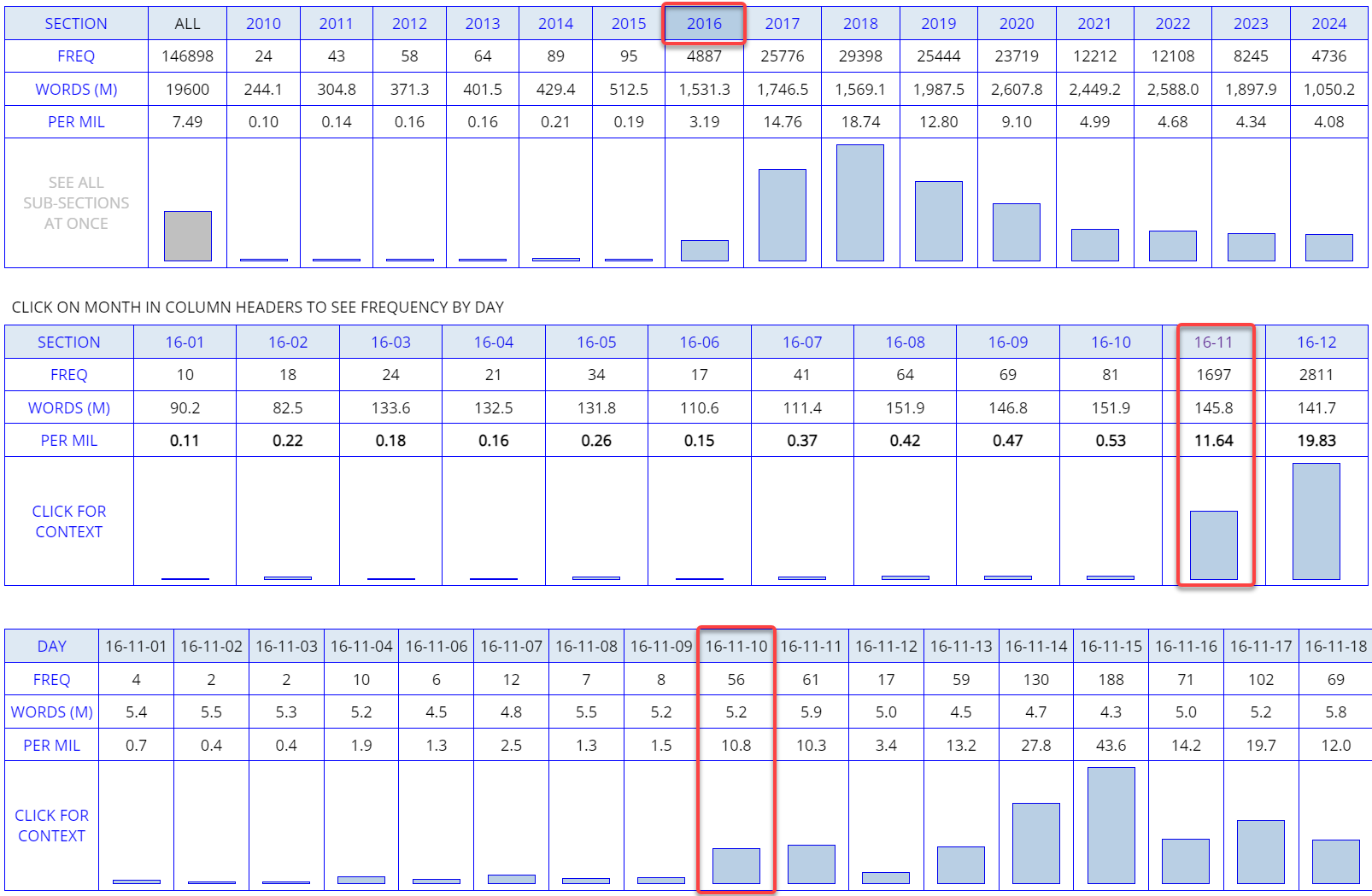
| In the
NOW Corpus (which
currently has almost 20 billion words from 2010 to the present, and
which grows by about 6-7 million words each day, or 200 million words
each month), it is even possible to see the frequency by year, month,
and day. For example, the chart to the right shows the frequency of
fake
news. Notice that it really starts to increase immediately
after the 2016 elections in the US, which took place on 8 November 2016. |
 |
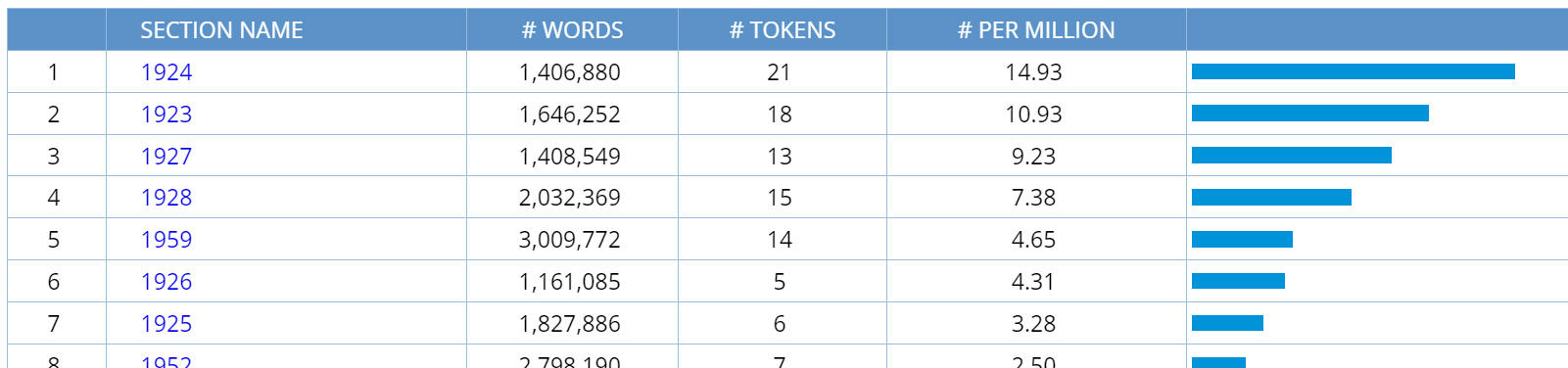
Finally, it is also possible to see the frequency in each of the different
"sub-sections", all at one time. For example, the following is the frequency of
flapper*
(see Wikipedia entry) in the
COHA corpus:

If you click on "See all years at once" (years are the sub-section in COHA),
then you will see the following, and you can resort the list by section (e.g. by
year in COHA) or by frequency.
The following are just a few sample CHART searches from some of the corpora. The
bottom line is that the corpora from English-Corpora.org help users to look at
variation --
between genres, or countries, or over time -- in ways that are not possible with
any other corpora.
| |
word |
phrase |
syntactic
construction |
COCA
(genres + time) |
(genres)
Hi!,
frowned,
championship,
correlated
(time)
seldom,
Y2K,
old-school,
smartphone |
(genres)
a lot
of NOUN,
several NOUN,
in
particular ,
(time)
old
school,
freak
out,
perfect storm |
like construction,
get
passive,
end
up V-ing,
appear to V,
must
VERB |
COHA
(decades) |
bestow,
swell (ADJ),
steamship,
flapper*,
fascist*,
teenage* |
of no little,
as though to,
freak out,
so ADJ
as to V,
BE
but,
HAVE
quite V-ed,
a most ADJ NOUN |
end up V-ing,
post-verbal negation with
need,
need to VERB,
HAVE
quite V-ed,
sentence initial
hopefully,
get
passive |
GloWbE
(countries) |
fortnight,
banjax*,
bikkies,
lah!,
thrice,
equipments
(PL) |
eve teas*,
BE different to,
rather more ADJ,
in over POSS head |
VERB likely VERB+,
like construction,
way construction,
try and VERB,
[stop] someone V-ing. |
NOW
(years, months+) |
Brexit,
birther,
impactful,
influencer* |
fake
news,
fidget
spinner*,
selfie
STICK,
virtue
signal* |
ended
up V-ing,
appeared to VERB,
dare
NEG VERB |
|