Number of texts: displaying, limiting, and sorting
 |
Note: click on any link
on this page to see the corpus data, and then
click on the "BACK" image (see left) at the top of the page to come back to
this page. Or right click on the link and then "Open link in new tab" (in
Chrome; similar in other browsers), and then close that tab after
viewing the corpus data. |
In addition to seeing the frequency of words and phrases, you can also see the number of texts in which these words and phrases occur, and sort and limit the results by the number of texts.
But why would you want to do this? Well, sometimes there are words or phrases that are limited to just a few texts in the corpus. If those texts weren’t in the corpus, the frequency of the word or phrase might be much lower, or it might not occur at all.
For example, consider these results for the search
cold NOUN in the
COHA corpus (the 475 million
word Corpus of Historical American English). Note that the screenshots here come
from the LIST view, but you can also see the number of distinct texts in the
CHART view, including the number of texts by sub-genre, year, etc.
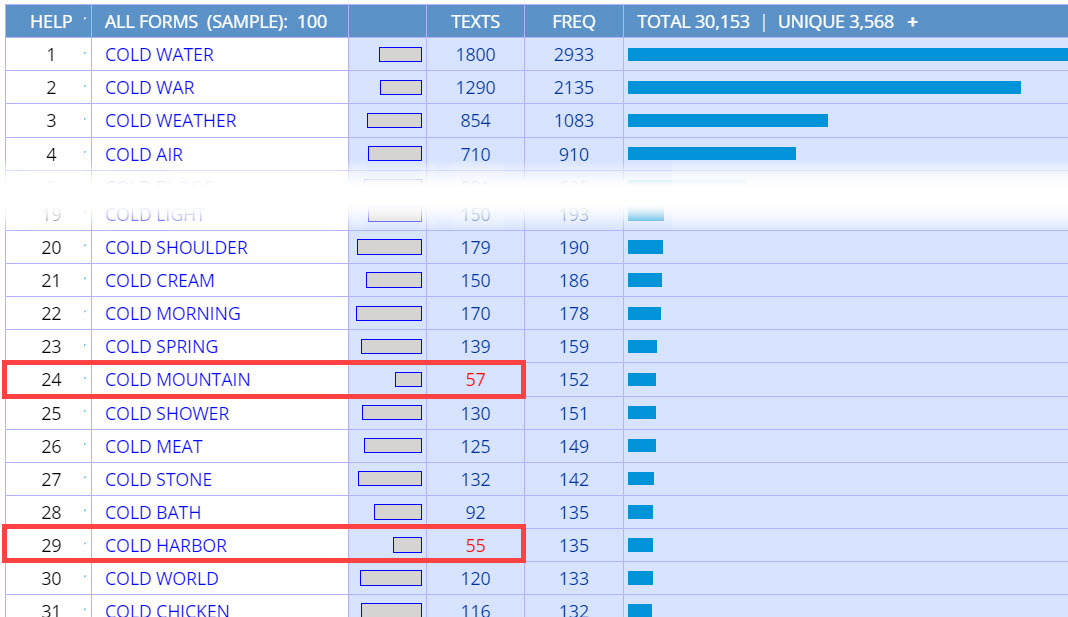
When you think of nouns that occur with cold, you might think of water, weather, shower, or bath, but probably not mountain or harbor, which are used mainly as place names in a limited number of texts.
This is often seen best in comparisons between one section of the corpus and another. For example, the following are the results for old NOUN in COHA, for the 1970s-2010s (left) and the 1840s-1890s (right). Notice that Old Hurricane only appears in two texts, and Old Sophy and Old Mirabel appear in one text each. (These are tagged as NOUN, but they probably should have been tagged as NAME: proper noun.)

And if we looked at the concordance lines for these phrases, they occur as the names of characters in just the one or two texts, as with Old Hurricane:

In other words, if the corpus didn’t have those few texts, the phrases might not occur in the corpus at all. But for phrases like old sinner (47 tokens in 35 texts) and old scenes (40 tokens in 37 texts), the phrases are spread out more through the entire corpus.
How to do it
|
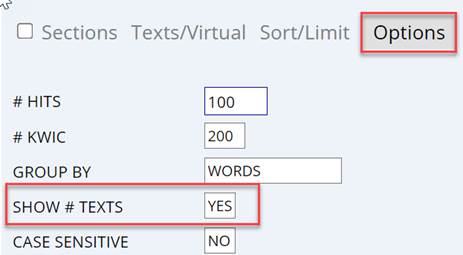
It is very easy to see the number of texts. In the search form, just click on [Options] and then set [Show # texts] to [YES].
|
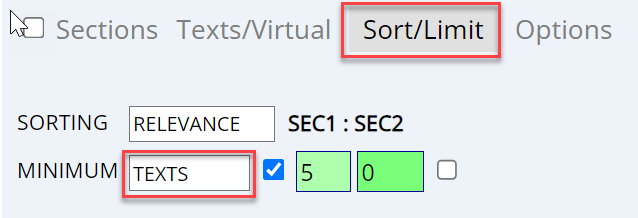 |
You can also sort the results by the number of
texts in which they occur -- use [SORT] in the search interface |
Perhaps more importantly, you can limit the results to just those words or phrases that occur in at least a certain number of texts. For example, if we set the
minimum number of texts to [5], then the results would be the following (notice that Old Hurricane, Old Sophy, and Old Mirabel are no longer there, since they did not occur in at least five texts):

|
In the results (such as for
words with *clean*, below), the number of texts (such as 315 for McLean) is highlighted in red when it is found in a limited number of texts. This is perhaps most useful when we have chosen to see the results by section in the search interface.
|

|


Notice that the 33 tokens of MacLean occur in only two texts in the 1860s and only four texts for the 138 tokens in the 1900s. This is pretty good evidence that this is the name of someone who is the focus of discussion in these handful of texts, rather than a word that is spread better throughout the section (such as cleansed or clean-cut).
Concordance display
You can also see information on the number of texts as part of the concordance display (also known as the Keyword in Context display, or KWIC), even if you haven’t chosen to see this in the frequency display. For example:
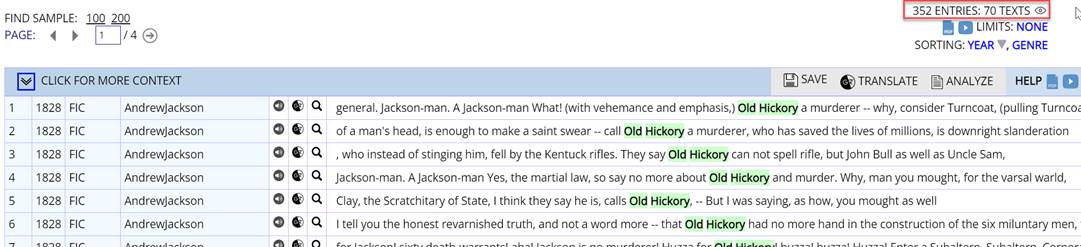
Finally, you can click on SHOW TEXT ID, which will indicate which entries are from the same text as the previous line (and which are highlighted in red):
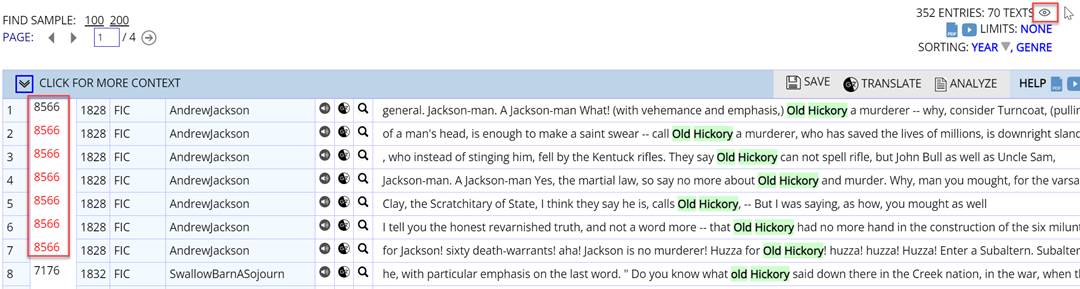
All of these features will make it easier for you to see which words and phrases are limited to just a few texts, and which ones are spread more evenly throughout the entire corpus.
|
