Note: click on any link
on this page to see the corpus data, and then
click on the "BACK" image (see left) at the top of the page to come back to
this page. Or right click on the link and then "Open link in new tab" (in
Chrome; similar in other browsers), and then close that tab after
viewing the corpus data.
Most of the information on how to use the corpora from English-Corpora.org is
found in the search interface itself. Just click on any of the links shown in
green or yellow.
One advantage of using the information in the corpus itself is that it is
context sensitive; for example, the information on how to search for collocates
appears as you click on [Collocates]. Another advantage is that the sample
searches are especially selected for that particular corpus.
(close)
In most cases, the examples in
these linked pages comes from the Corpus of Contemporary American English
(COCA), since it is the most widely used of the corpora from English-Corpora.org
(and probably the most widely-used online corpus anywhere).
A number of examples also come from
COHA (historical),
GloWbE (dialects), and
NOW (very large and recent). But all of the information in these help files should
be applicable to any of the 17 corpora at English-Corpora.org.
(close)
Please note that these pages were recently released (in September
2024), and there are probably still some errors, since English-Corpora.org has
been created and is run by just one person. If you find anything that needs to be corrected, please
email us. Thanks.
(close)
Option
Search form
# HITS
The number of results. The maximum is 1000 or 4000, depending on the
type of search.
# KWIC
The number of results for a KWIC (concordances) search. The default is 200, but
you can see as many as 1000.
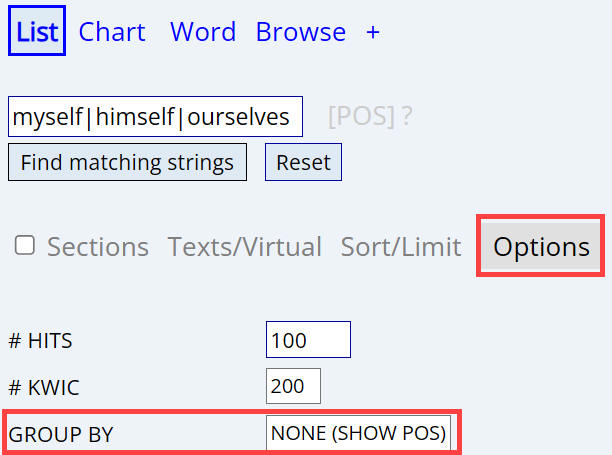
GROUP BY
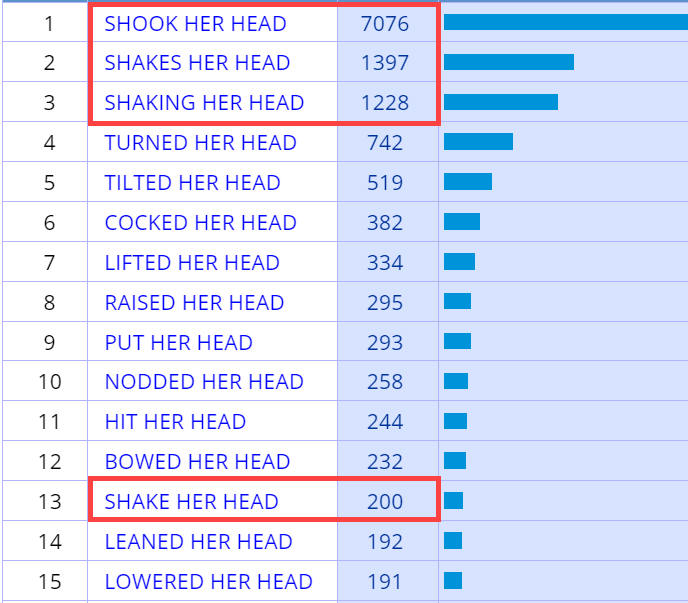
Determines whether words are grouped by word form (e.g. shake, shakes,
shaking, shook separately),
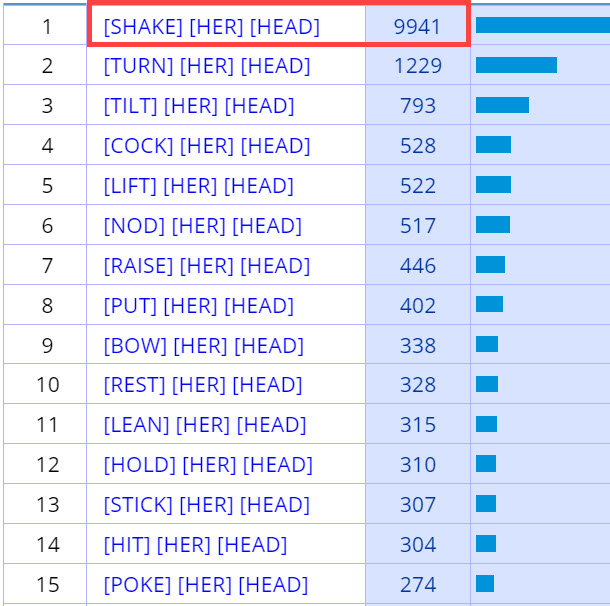
lemma (e.g. all forms of shake together). For example, the
first example below (for the search VERB her head)
does not group the entries for shake, while the second search does group
the entries (and note that the lemma (headword) is in brackets). NONE (SHOW POS) shows the the part
of speech for each word in the list (e.g. back
as a noun, verb, adjective, adverb, preposition, etc).
Group by word
Group by lemma
Group by word / part of speech (NONE - SHOW POS)
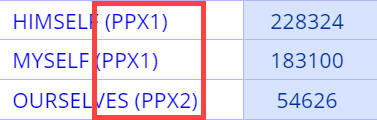
NONE (SHOW POS) can be useful when you don't know the part(s) of speech (PoS)
for a given word or phrase. For example, suppose that you want to know the part
of speech of words like
myself, himself, ourselves, etc, because you want to do other searches with
that part of speech (whatever it is). Do the search, with OPTIONS / GROUB BY set
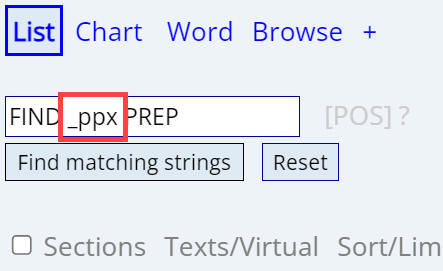
to NONE (SHOW POS). It looks like what they have in common is
ppx. Try using that part of speech in another search, and refine the PoS
code if necessary.
1. Enter word(s)
2. See part of speech (PoS)
3. Use PoS in other searches
4. See results; refine if necessary
SHOW # TEXTS
Determines whether you see the number of texts in which a word or phrase occurs,
in addition to its frequency. This can be useful in finding words and phrases
that are limited just to a few texts in the corpus.
(More
information)
CASE SENSITIVE
Determines whether She thought and she
thought would be two different searches, or The Office, the Office,
and the office. The default is non
case sensitive. For example, if set you
[NO], then the search the bushes
(or the Bushes, or any other combination of upper and lower
case letters) would find cases referring to the plants and to the family (for
example, George H.W.
Bush and George W.
Bush). If it is set to [YES],
then the
bushes
would refer to just the plants but not the family, and the
Bushes
would refer to the family but not the plants. (Click on the results to see the
KWIC / concordance entries, to see the difference between the two searches /
meanings). Search like this be especially
helpful when a word appears both as a proper noun and a common noun.
DISPLAY
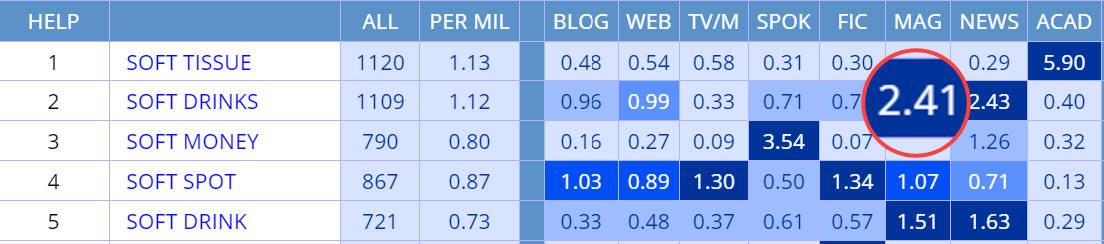
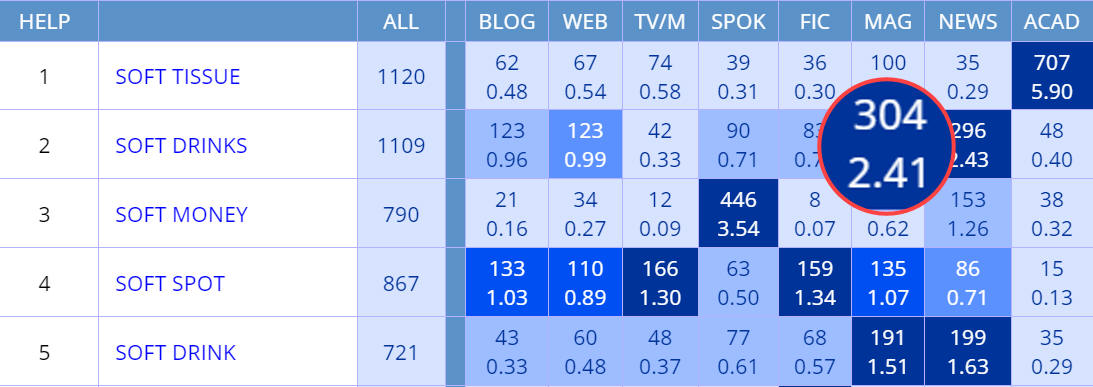
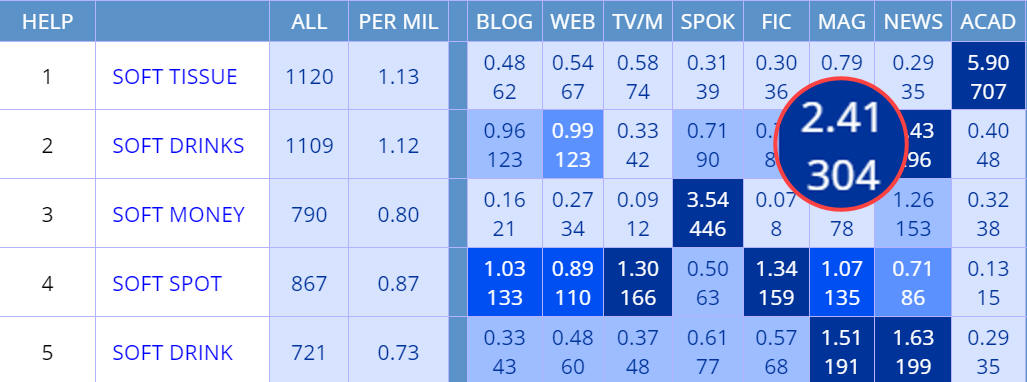
Shows raw frequency, occurrences per million words, or a combination of
these. For example, the following are the results of soft NOUN in COCA,
showing raw
frequency (the default),
frequency per
million words,
raw frequency
and frequency per million, and
frequency per
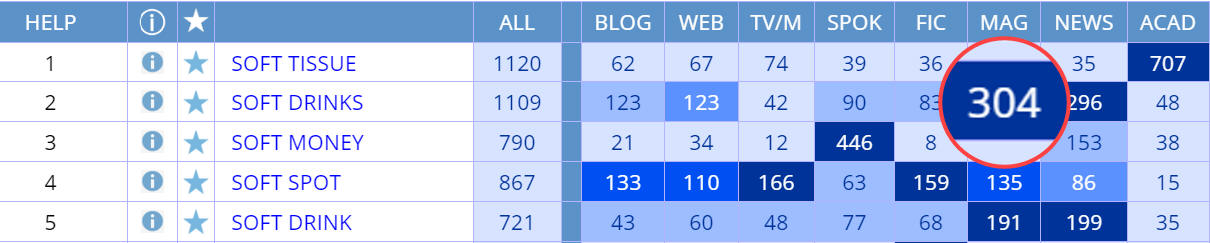
million and raw frequency. Note that the enlarge numbers (for soft drinks in
the Magazines genre) is just for display purposes on this current web page.
Finally, note that no matter which option is chosen, if you choose to see the
frequency in each section of the corpus (for example genres in
COCA, decades in
COHA, or countries in
GloWbE), then the color of
the cell reflects the relative frequency of the string in each of the sections.
For example, soft tissue is the most frequent in academic, soft drinks
in magazines and newspapers, and those sections have the darkest blue cell
color.
This allows you to create a wordlist from the results and then re-use it
later in your searches. For example, you could do a search to find synonyms of
beautiful, and then select just the words that you want for your own customized
word list. More information:
PDF (page 2),
video.