In our corpora, Mutual Information is
calculated as follows:
MI = log ( (AB *
sizeCorpus) / (A * B * span) ) / log (2)
Suppose we are
calculating the MI for the collocate color near purple in
BNC.
A = frequency of node word (e.g.
purple):
1246
B = frequency of collocate (e.g. color):
112
AB = frequency of collocate near the node word (e.g. color near
purple):
22
sizeCorpus= size of corpus (# words; in this case the BNC):
96,263,399
span = span of words (e.g. 3 to left and 3 to right of node word): 6
log (2) is literally the natural log of the number 2: 0.6931
MI = 11.30 = log ( (22 * 96,263,399) /
(1246 * 112 * 6) ) / 0.6931
And just a quick note about the presumed
shortcomings of the Mutual Information score. The most serious (or only real?)
issue is that MI gives strange results when the frequencies are very low -- e.g.
1-3 tokens. But with the corpora from English-Corpora.org, you can set a minimum frequency
for the collocates, which takes care of most of the problem.
Let's now compare our Mutual Information (MI) scores
to those in BNCweb and
Sketch Engine
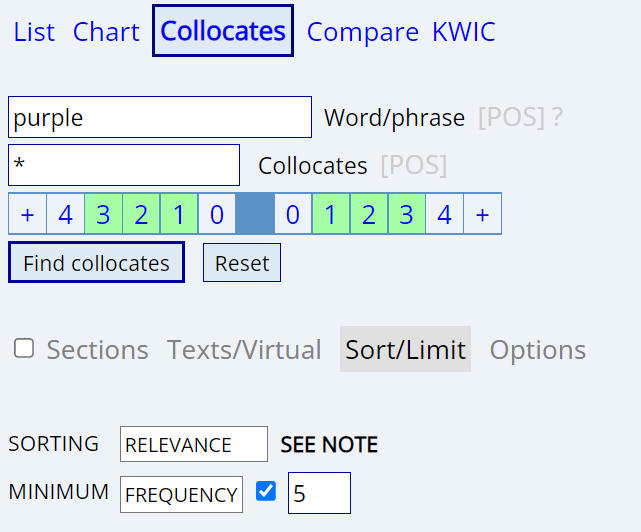
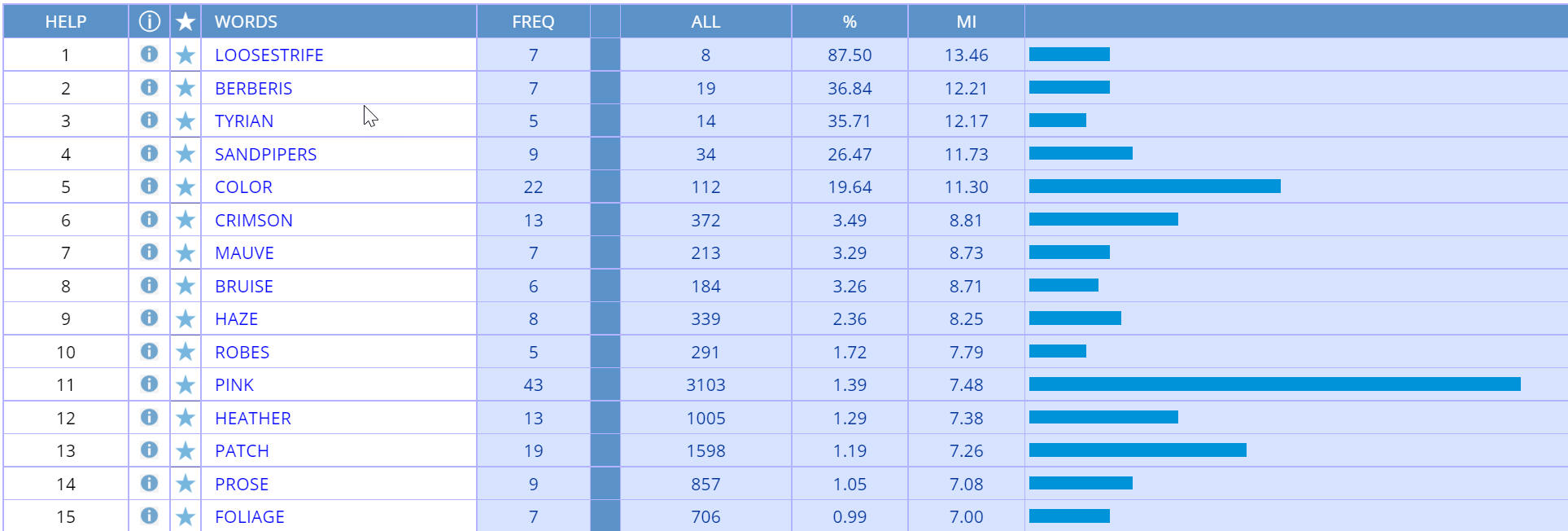
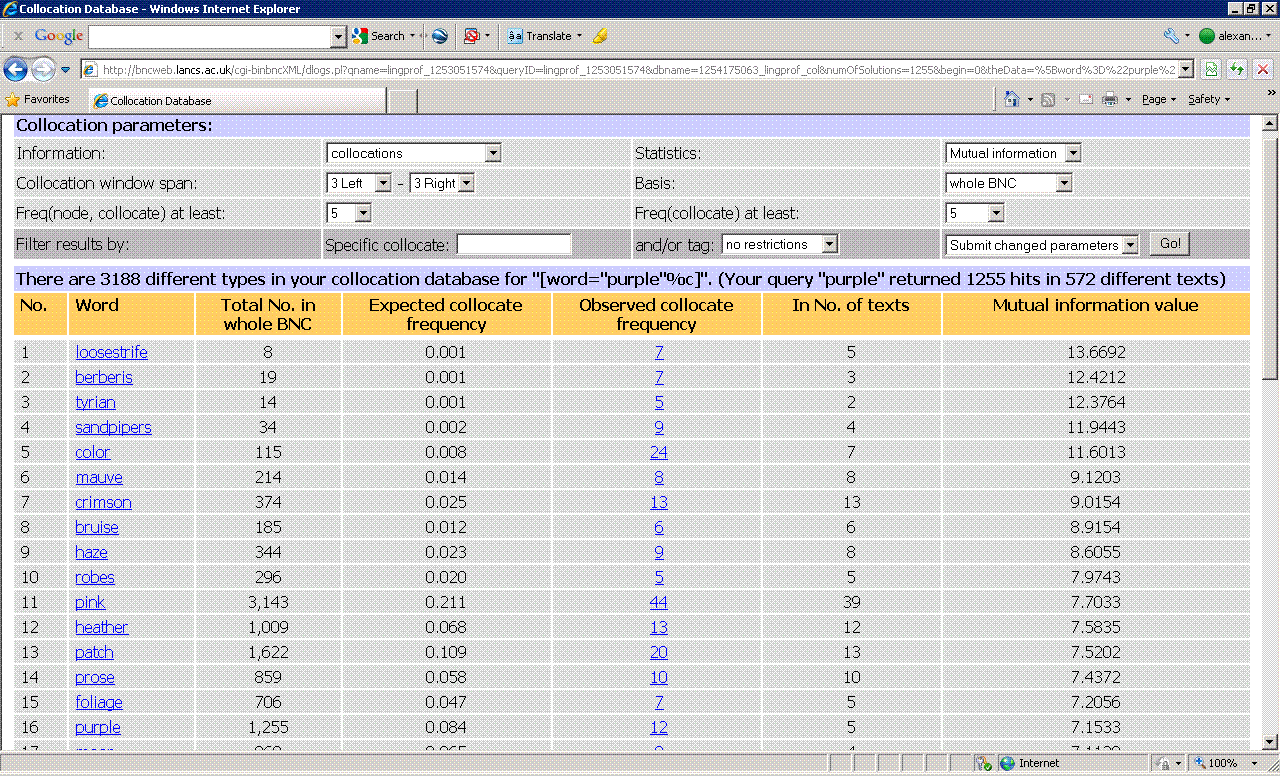
The following are the results for the highest-ranked collocates by Mutual
Information score for the word purple in the BNC, with the span set to [3L/3
R] and a minimum collocate frequency of [5] (run
query).
Notice in the screen shots below that BNCweb and our BNC agree very well -- the rank order is exactly
the same and the MI score is within 2-3% for each collocate. Apparently both
architectures are using the same MI calculation and the small, consistent
difference here is likely due to the way in which the two architectures count
the total number of words in the corpus.
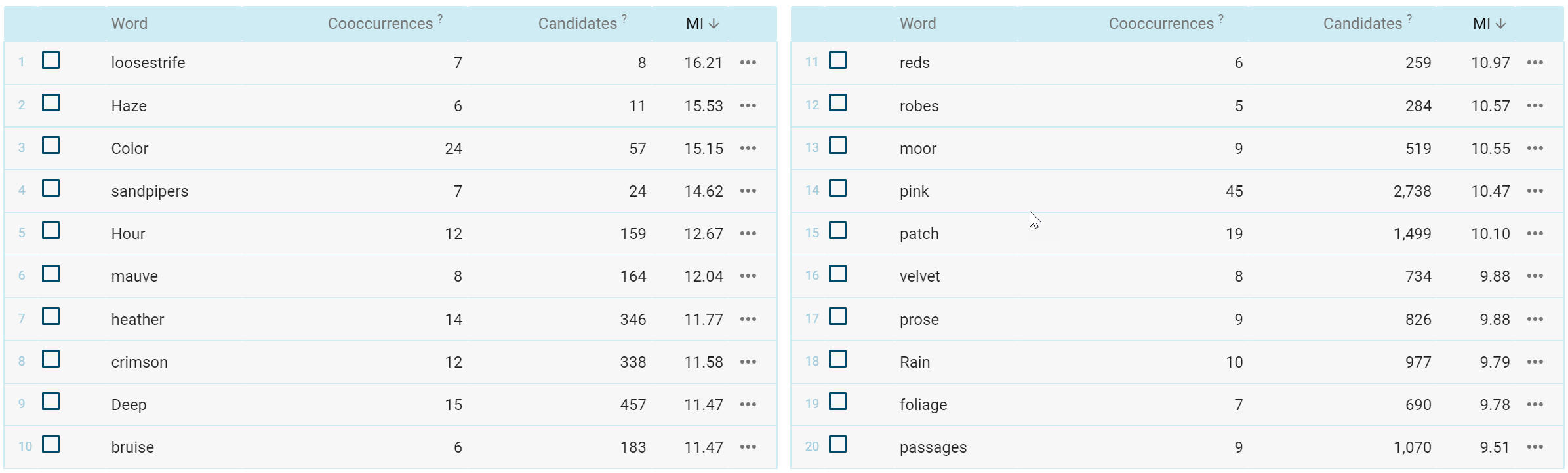
Although it is labeled as
standard "Mutual Information", Sketch Engine actually uses a slightly different
calculation: "a scaled version of Dice" (Adam Kilgarriff, p.c.). Note that 3 of
the top 12 collocates are different in SE (hour, deep,
and reds) and the rank order of
collocates is not the same as in our BNC and BNCweb. This also gives "MI scores" in Sketch Engine are 20-80% higher than in BNCweb and our BNC,
depending on the collocate.
BNC (English-Corpora.org)
BNCweb
Sketch Engine
|