Collocates (search
form,
corpora used,
corrections,
+/- sections;
compare to
Word / phrase and
Topics
searches; word comparisons)
Collocates (search
form,
corpora used,
corrections,
+/- sections;
compare to
Word / phrase and
Topics
searches; word comparisons)
 |
Note: click on any link
on this page to see the corpus data, and then
click on the "BACK" image (see left) at the top of the page to come back to
this page. Or right click on the link and then "Open link in new tab" (in
Chrome; similar in other browsers), and then close that tab after
viewing the corpus data. |
In most cases, the examples in
these linked pages comes from the Corpus of Contemporary American English
( COCA), since it is the most widely used of the corpora from English-Corpora.org
(and probably the most widely-used online corpus anywhere).
A number of examples also come from
COHA (historical),
GloWbE (dialects), and
NOW (very large and recent). But all of the information in these help files should
be applicable to any of the 17 corpora at English-Corpora.org.
(close)
Please note that these pages were recently released (in September
2024), and there are probably still some errors, since English-Corpora.org has
been created and is run by just one person. If you find anything that needs to be corrected, please
email us. Thanks.
(close)
Collocates allow
you to see what words occur in a "cloud of words" near a given word or phrase
(called the "node word"). The "default" number is four words to the left and
four words to the right of the node word, but you can change this (for example,
adjectives
"near" taste; 3 words left to 3 words right). These are different from
word / phrase queries,
which are a defined, linear string of words (for example, two words
strings composed of
ADJ taste)
Note that phrase searches are usually faster (sometimes much faster)
than collocates searches -- so don't do a collocates search when a
phrase search is all you need.
Collocates can provide great insight into meaning and usage. For example, look at the collocates near
sprawl
(n), bodice,
alabaster,
climate
change, or
health care. Now compare these collocates with a Google Image search for some
of the same node words:
sprawl,
bodice,
alabaster. Notice how well the
collocates paint a "word picture" of the node word.
And in many cases, the
collocates provide insight into the meaning and use of a word that goes far
beyond what a dictionary would show. For example, the collocates of
sprawl
(alternate
view; see below)
include pollution, congestion, impact (nouns) and reduce, prevent,
threaten (verb). This suggests that sprawl is something that people
are concerned about, and this is the type of information that would probably not
appear in a dictionary; but rather it is something that native speakers
inherently "understand" about the word.
Collocates field: types of searches
For both the WORD and COLLOCATES field, you can include the full range of
searches, including words, lemmas, substrings, parts of speech, and synonyms.
For example, the following are searches for collocates of gap (n): any
word, nouns, adjective, the
word fill, synonyms
of large.
Direction / distance
|
|
Select the "span" (number of words to the left and the right) for the
collocates. Use + to search more than four words to the left or right, and
0 to
exclude the words to the left or right. If you don't select a span, it will
default to 4 words left and 4 words right. |
|
The direction of the collocates and the length of the "span" between the "node
word" and the collocates is quite important. For example, consider the
collocates of car: 2
words to the left, 1
word to the right, 4
words to the right, and 3
words left / 3 words right. |
Other association measures
Some other corpus sites provide a much wider range of "association measures",
which show how related two words are in terms of their co-occurrence in a
corpus. But
as we
have shown in great detail elsewhere, these measures (while appearing very
fancy) are actually quite unnecessary. It is basic word frequency (with Mutual
Information simply acting as a filter) that provide the best insight into
meaning and usage, especially for language learners.
Collocates in COCA and iWeb
In COCA and
iWeb, the default display for collocates
will group the collocates by
part of speech (noun, verb, adjective, and adverb), as is shown in this example
for kombucha
in the 14 billion word iWeb corpus:
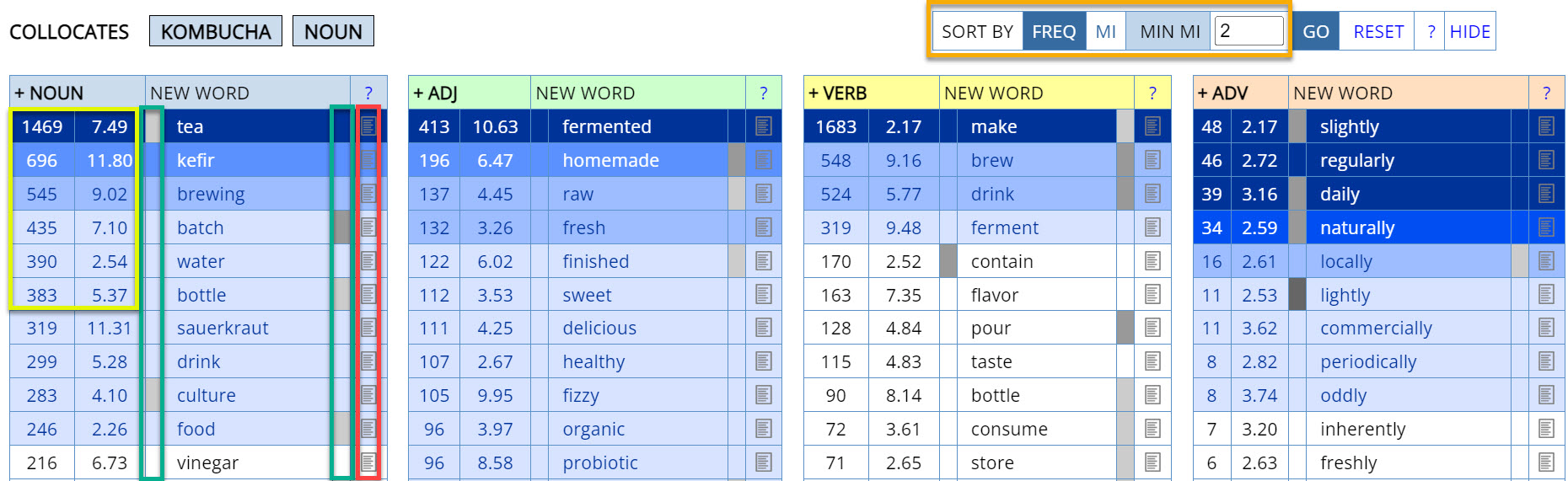
This display shows the frequency and Mutual Information for each word (shown
in yellow here), and whether the node word tends to occur more before or after
the collocate (shown in green here; for example, culture + kombucha, but
batch + kombucha). By clicking on the link (shown here in red), you can see the KWIC
(Keyword in Context) lines, and you can choose different options for sorting and
limiting (shown here in orange).
In COCA and iWeb, you will see this format for collocates when 1) you use the
default of 4 words left / 4 words right and 2) your choice for collocates is *
(any word) or NOUN, VERB, ADJ, or ADV. So in COCA and iWeb, if you
don't want to see the collocates in this format (but rather you want
the more
basic format), then change the collocates range, for example, from 4 Left /
4 Right to something else, like 3 Left / 4 Right, or 4 Left / 5 Right.
Variable length collocates queries
You can use collocates to do "variable length" searches, where there might
be 0-4 (or more) words between two other sets of words or phrases. For
example, you could find all of the following with one simple search.
(were) talked into coming (0 words)
talk them into coming (1 word)
talk the girls into coming (2 words)
talk some other people into coming (3 words)
talk lots of other people into coming (4 words)
In the sample queries below, you would
enter the following in WORD(S),
COLLOCATES,
and
the maximum
length in words (up to nine words, left and right) between WORD(S) and COLLOCATES. For example, O L | 4 R means the
COLLOCATES are between 0 words to the left and 4 words to the right of
WORD(S).
Click on
A , B ,
or C
below to run the sample queries.
| # words |
construction |
|
A
|
VERB NOUN PHRASE
into _vvg |
|
1 L | 0 R |
VERB her
into _vvg e.g. talked
her into staying |
|
2 L | 0 R |
VERB the people
into _vvg |
|
4 L | 0 R |
VERB my best
friend into _vvg |
|
|
|
|
B
|
EXPECT
[a*]|[d*]|[n*]|[p*]
NOUN PHRASE
[v?i*] |
|
0 L | 2 R |
EXPECT
them to
[v?i*] (
them = [p*] pronoun ) |
|
0 L | 3 R |
EXPECT
Bill Clinton to
[v?i*] (
Bill = [np*] proper noun ) |
|
0 L | 4 R |
EXPECT
those six people to
[v?i*] (
those = [d*] demonstrative ) |
|
0 L | 5 R |
EXPECT
the people in Florida to
[v?i*]
( the = [a*] article ) |
|
|
|
|
C
|
what|all
RELATIVE CLAUSE do [be] VERB
(in the 200 million word
Movies corpus) |
|
4 L | 0 R |
what|all he wants
to do BE VERB
e.g.
what|all he wants to do is complain |
|
5 L | 0 R |
what|all they
expected Fred to do BE VERB |
|
7 L | 0 R |
what|all
any of these crazy people can do BE VERB |
|
8 L | 0 R |
what|all
your best friend can possibly hope to do BE VERB |
|
Note |
Use [a*]|[d*]|[n*]|[p*]
to look for the first word of a noun phrase (you may want to refine
this further). You can also use the negator
- to indicate NOT,
e.g. -VERB|ADV
(not verb or adverb) or -to|will|would
(none of these three words). Make sure there is no space to the left or
right of | when there
is a series of elements. |
Notes:
1. The green (collocates) portion can only have one word, not a sequence of
two or three words. For this one word, however, there can be any number
of possibilities, such as either what or all in [C] above.
2. Not all
of the KWIC entries will in fact be relevant, because we haven't placed
any constraints on what is between the yellow and the green parts of the
search. But using the yellow portion as an "anchor" is still far better
than searching for just the green portion.
3. Another option is to use the
variable
length LIST search. The advantage of that approach is that you
can see (and limit) the intervening words. The disadvantage is that the
"variable length" section is limited to three words.
|