Compare words (search
form,
corpora used,
corrections,
+/- sections;
compare
to
Collocates
searches)
Compare words (search
form,
corpora used,
corrections,
+/- sections;
compare
to
Collocates
searches)
 |
Note: click on any link
on this page to see the corpus data, and then
click on the "BACK" image (see left) at the top of the page to come back to
this page. Or right click on the link and then "Open link in new tab" (in
Chrome; similar in other browsers), and then close that tab after
viewing the corpus data. |
In most cases, the examples in
these linked pages comes from the Corpus of Contemporary American English
( COCA), since it is the most widely used of the corpora from English-Corpora.org
(and probably the most widely-used online corpus anywhere).
A number of examples also come from
COHA (historical),
GloWbE (dialects), and
NOW (very large and recent). But all of the information in these help files should
be applicable to any of the 17 corpora at English-Corpora.org.
(close)
Please note that these pages were recently released (in September
2024), and there are probably still some errors, since English-Corpora.org has
been created and is run by just one person. If you find anything that needs to be corrected, please
email us. Thanks.
(close)
Important information about limits and sorting.
You can compare the collocates of
two words, to see how they differ in meaning and usage. For example, compare the
noun collocates of utter
and complete + NOUN (note
the negative collocates with utter) or
warm
/ hot or small
and little,
or the adjectives near boys
and girls or
Democrats
and Republicans, or the objects of
destroy / ruin or
sanction / approve.
By comparing collocates, you can move far beyond the simplistic entries in a
thesaurus, to "tease out" slight differences in words, or (as in the case of boy and girl )
what is the difference in what is being said about two different things.
Setting up the search
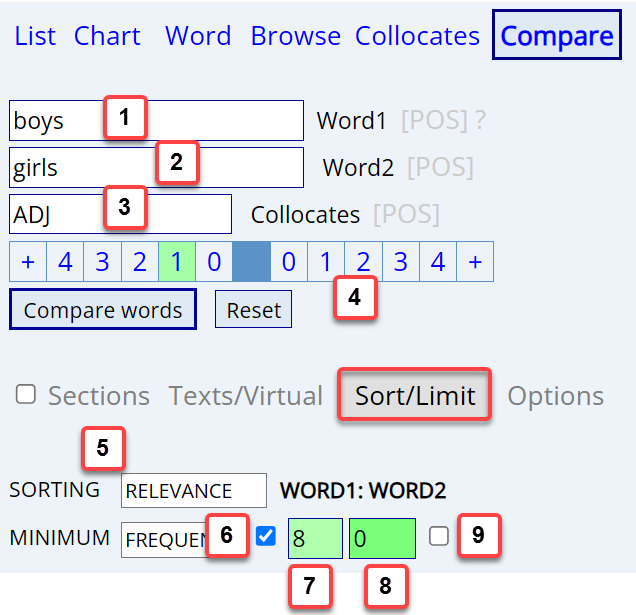 |
The only thing that you need to input into
the search form are the two words ([1]
and [2] in the image to
the left). But by changing some of the options, you might get better
results:
[3] Limit the collocates
to a particular part of speech. For example, cars vs trucks:
all
collocates,
just
adjectives
[4] The "span" in which
the collocates occur. The default is 4 word left / 4 words right. But in
a case like utter vs complete, where it is mainly just the
one word to the right that is important (utter nonsense /
complete nonsense), you can limit the search to that one "slot" and
the search will be much faster.
Click here for help on Sorting and
Limits ( [5]
to [9] ). |
Interpreting the results
The following are the first few lines from the results of a search comparing
the nouns immediately after
utter
and complete in COCA.
A different search (in another corpus) will of course yield different results, but the general concepts remain the same.
Before you try to interpret the numbers, notice how much the collocates of
utter are much more negative than those with complete (this is an
example of semantic
prosody).
|
WORD 1 (W1) UTTER 1 (5812)
3
(.06)
5
|
|
|
WORD
7 |
W1
8 |
W2
9 |
W1/W2
10 |
SCORE
11 |
|
1 |
DESOLATION |
25 |
3 |
8.3 |
132.0 |
|
2 |
CONTEMPT |
105 |
15 |
7.0 |
110.9 |
|
3 |
FOLLY |
19 |
3 |
6.3 |
100.3 |
|
4 |
HELPLESSNESS |
16 |
3 |
5.3 |
84.5 |
|
5 |
STUPIDITY |
46 |
9 |
5.1 |
81.0 |
|
6 |
AMAZEMENT |
43 |
11 |
3.9 |
61.9 |
|
7 |
HOPELESSNESS |
21 |
6 |
3.5 |
55.5 |
|
8 |
DISBELIEF |
69 |
20 |
3.5 |
54.7 |
|
9 |
ABSURDITY |
17 |
5 |
3.4 |
53.9 |
|
10 |
MADNESS |
32 |
10 |
3.2 |
50.7 |
|
11 |
DISGUST |
34 |
11 |
3.1 |
49.0 |
|
12 |
DESPAIR |
57 |
19 |
3.0 |
47.5 |
|
|
WORD 2 (W2) COMPLETE
2 (92087)
4
(15.84)
6
|
|
|
WORD |
W2 |
W1 |
W2/W1 |
SCORE |
|
1 |
LIST |
803 |
0 |
1,606.0 |
101.4 |
|
2 |
PICTURE |
585 |
0 |
1,170.0 |
73.8 |
|
3 |
SET |
437 |
0 |
874.0 |
55.2 |
|
4 |
UNDERSTANDING |
304 |
0 |
608.0 |
38.4 |
|
5 |
GUIDE |
294 |
0 |
588.0 |
37.1 |
|
6 |
GAME |
293 |
0 |
586.0 |
37.0 |
|
7 |
DATA |
251 |
0 |
502.0 |
31.7 |
|
8 |
INFORMATION |
248 |
0 |
496.0 |
31.3 |
|
9 |
WORKS |
227 |
0 |
454.0 |
28.7 |
|
10 |
COVERAGE |
216 |
0 |
432.0 |
27.3 |
|
11 |
STORY |
203 |
0 |
406.0 |
25.6 |
|
12 |
DESCRIPTION |
181 |
0 |
362.0 |
22.8 |
|
The basic idea of the table is that we want to see how frequent a
collocate is with two competing words, compared to the overall
frequency of those two words. For example, if there are twice as
many tokens of Word1 as Word2 in the corpus overall, but a given
collocate occurs fifty times as much with Word1 as with Word2, then
the ratio of Word1 to Word2 with that collocate is 25 times what
would otherwise be "expected".
1,
2.
The two words being compared
3, 4.
The overall frequency for the two words. In this
example, there are 5812 tokens of utter and 92087 tokens of
complete.
5, 6. The ratio of the frequency of the two words. For
example, there are .06 tokens of utter for every token of
complete in the corpus, and 15.84 tokens of complete for
every token of utter. In other words, because complete is about
16 times as frequent as utter, any collocate (all
things being equal) should occur about 16 times more frequently with
complete than with utter.
7.
The rank-ordered list of words or phrases that occur with [1].
Click on the word or phrase to see the "Keyword in Context" display.
8.
The frequency of [7] with [1]. In this case we looked for nouns
after utter, so this indicates that there were 16 tokens of
utter helplessness (the fourth entry on the left).
9.
The frequency of [7] with the competing word [2]. In this case, it
shows that there are just 3 cases of complete helplessness.
10.
The ratio of [8] / [9]. In this case, there are 5.3 times as many
cases of utter helplessness as there are complete
helplessness (When the competing word has a frequency of 0, it is set to .5, to
avoid division by 0.)
11.
The ratio of [10], compared to [5]. Remember that there should be about .06 tokens with
utter for every token with complete, since that is the
overall ratio of the two words in the corpus. In the case
of helplessness, though, the ratio of
[utter/complete] is 5.3, which is 84.5 times the "expected"
frequency of .06.
The results are sorted by the decreasing figures in this column.
Note that in the example above, the entries are sorted by the
"score", which is a function of the ratio of the two
words. But if you just want to see which are the most frequent
strings with each word (regardless of what is happening with the
other word), then select OPTIONS / [SORT BY] = [FREQUENCY] in the
search form.
|