Sorting / limiting results (search
form,
corpora used,
corrections,
+/- sections)
Sorting / limiting results (search
form,
corpora used,
corrections,
+/- sections)
 |
Note: click on any link
on this page to see the corpus data, and then
click on the "BACK" image (see left) at the top of the page to come back to
this page. Or right click on the link and then "Open link in new tab" (in
Chrome; similar in other browsers), and then close that tab after
viewing the corpus data. |
In most cases, the examples in
these linked pages comes from the Corpus of Contemporary American English
( COCA), since it is the most widely used of the corpora from English-Corpora.org
(and probably the most widely-used online corpus anywhere).
A number of examples also come from
COHA (historical),
GloWbE (dialects), and
NOW (very large and recent). But all of the information in these help files should
be applicable to any of the 17 corpora at English-Corpora.org.
(close)
Please note that these pages were recently released (in September
2024), and there are probably still some errors, since English-Corpora.org has
been created and is run by just one person. If you find anything that needs to be corrected, please
email us. Thanks.
(close)
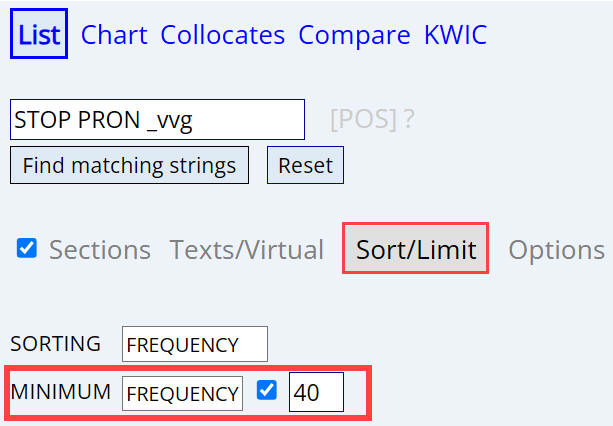
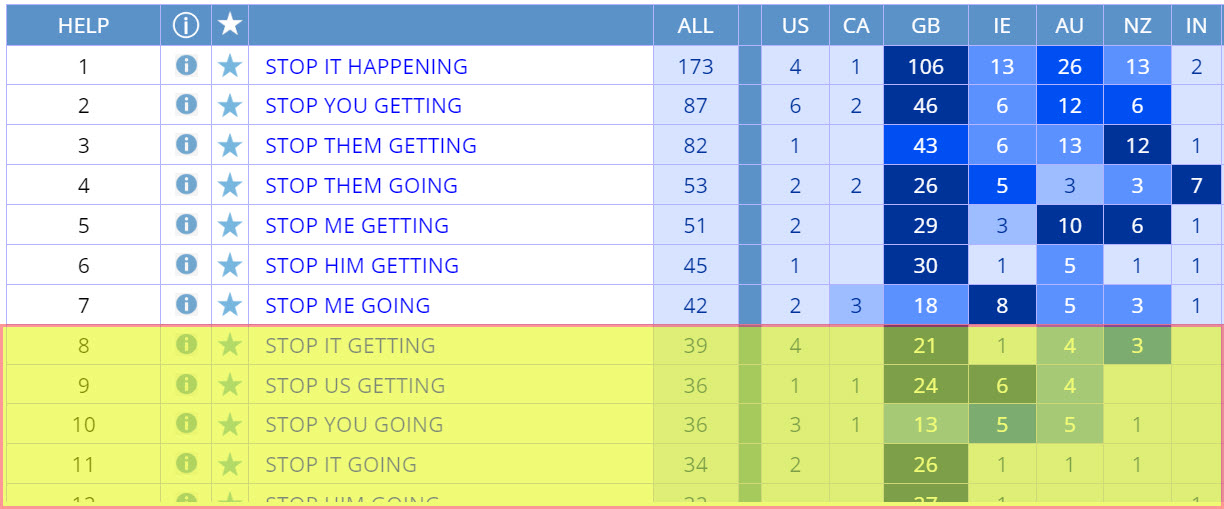
Limiting entries At the most basic level, you can set
a lower limit for the frequency of the results. For example, if you don't
set a lower limit for the search
STOP
PRON _vvg in the
GloWbE corpus (for example stop it happening, where it would be
stop it from happening in the US/CA), then you would see all
of the entries shown in the list below. But if you
set a
minimum frequency of 40, then you would see just the first seven
entries. This can be the most useful when you're seeing very low frequency
entries that don't seem to relate much to the search that you've done.
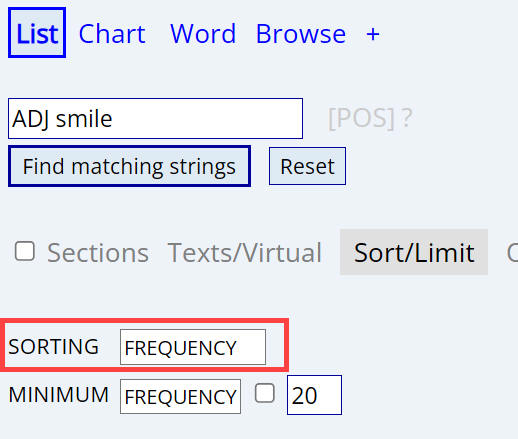
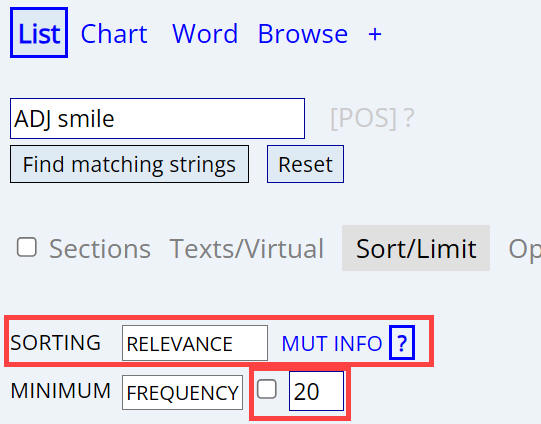
Sorting entries: phrase
For most searches, the default sorting is by frequency. For
example, if you search for
ADJ smile,
you will see that the most frequent strings are big, little, small +
smile. But big, little, and small occur with lots of
nouns, not just smile. In other words, they don't really tell us much
about smile.
| Frequency |
 |
 |
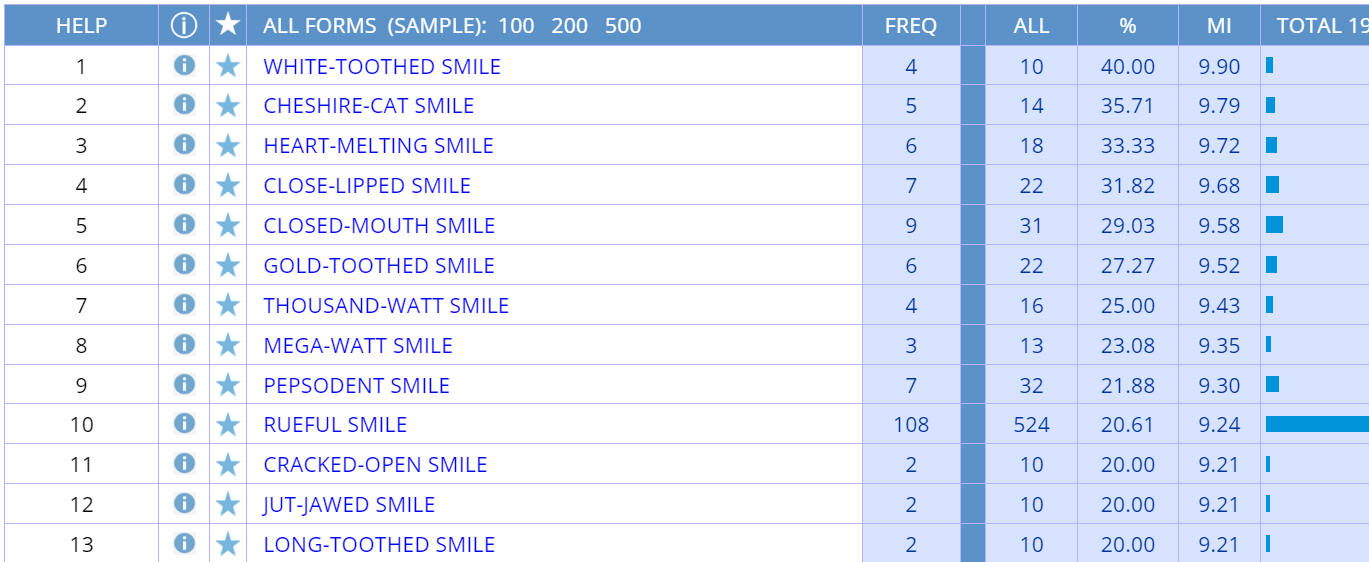
But if we
sort by
relevance, then we see the words that are especially "attracted"
to smile. For example, rueful occurs with smile 108 times in
the COCA corpus ( 1 below)
and rueful occurs only 524 times overall in the corpus (
2 ). In other words, 20.6% (
3 ) of all of the tokens of rueful in the corpus occur with
smile, and so if someone said the word rueful, native speakers
might easily think of smile. The Mutual Information score (
4 ), which is directly tied to the percentage (
3 ), is 9.24, which is quite high. And then (
5 ) provides a bar chart that shows the relative frequency of each of
the phrases.
Relevance
(Percentage /
MutInfo) |
 |
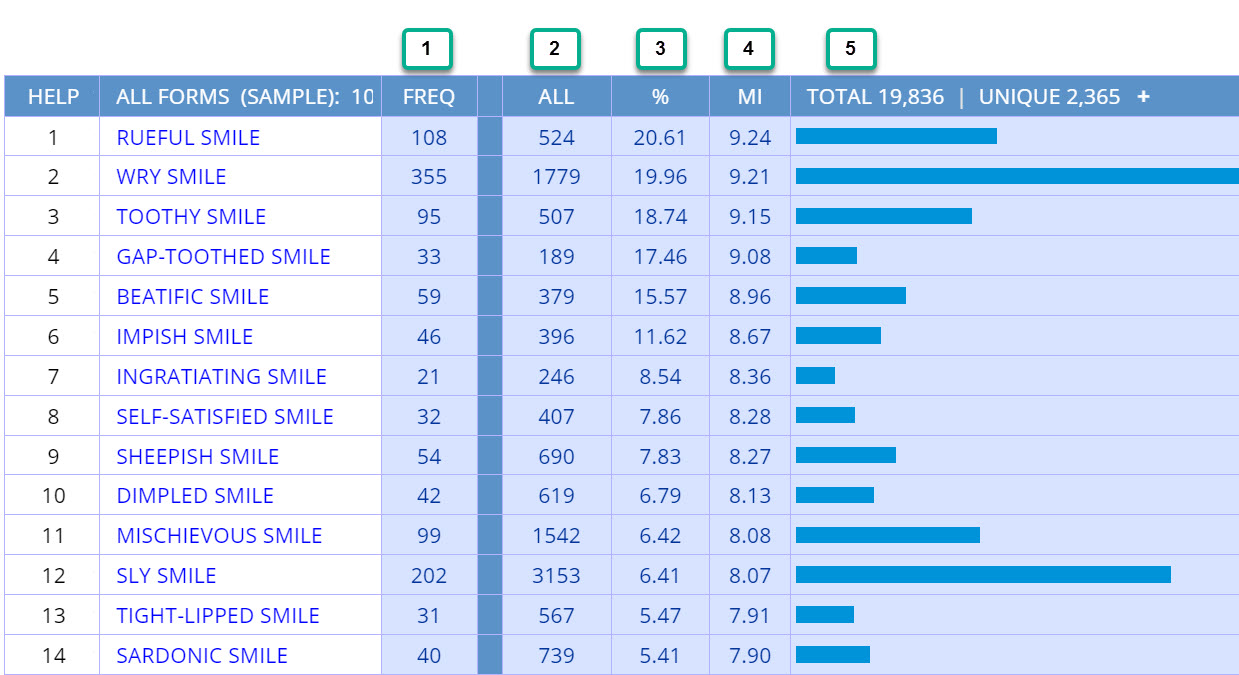 |
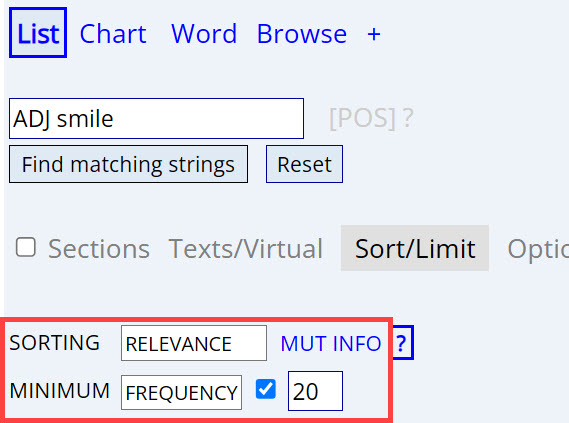
But you need to be careful when using the "relevance" (percentage /
Mutual Information) sorting. If you don't click the checkbox next to
[Minimum Frequency], then you will probably get some strange very low
frequency phrases. They have a high relevance (Mutual Information) value, in
the sense that a high percentage of all of the tokens of a given word (for
example cracked-open, below) do occur with the other word (for
example smile). In this case, 20% (2 of 10) tokens of cracked-open
occur right before smile. But two tokens (in a corpus like COCA,
which has one billion words) is pretty small. By default, when you click on
[Sorting: Relevance], it will select that checkbox and set a good minimum
value for the corpus that you're using (with higher values for larger
corpora). You can adjust this if you want -- higher number for fewer
low-frequency strings, lower number for more low-frequency strings. But
again, if you set it too low (or don't click the checkbox at all), you may
get some strange, low-frequency strings.
Relevance (Perc/MI)
No frequency filter |
 |
 |
Limiting and sorting with collocates
Above we were looking at strings with a certain number of words, for
example the two word string ADJ smile. You can also search for
collocates, which are words occurring anywhere within a "cloud of
words" around a node word -- for example, ADJ (adjectives) anywhere within a
cloud of words from 4 words left to 4 words right of the word car.
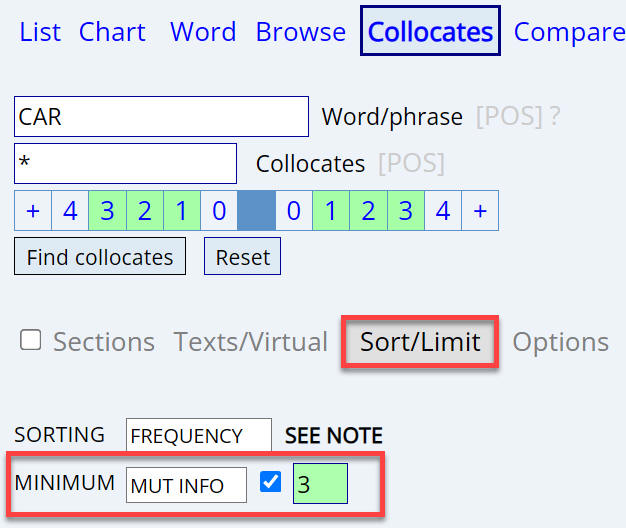 |
With collocates, if you don't manually
select anything (including the collocate, such as ADJ), then it will
default
to [Frequency] with Relevance (Mutual Information)
as a filter. What this means is that it will filter out very high
frequency words like the, are, and, or thing. These words
might be found a lot near your node word (in this case, car), but they are found in many
other contexts as well, meaning that they aren't especially related to
your node word. If you set the
Mutual Information
score to a lower
number (such as
1.0)
it will show more of these generally high frequency words in English,
such as small or use with telescope. If you set it
higher (for example
7.0)
will show those words that are especially related to the node word --
but at the risk of not showing collocates that provide basic meaning
about the word, such as space or sky with telescope.
A value of
3.0
is probably a good starting point. |
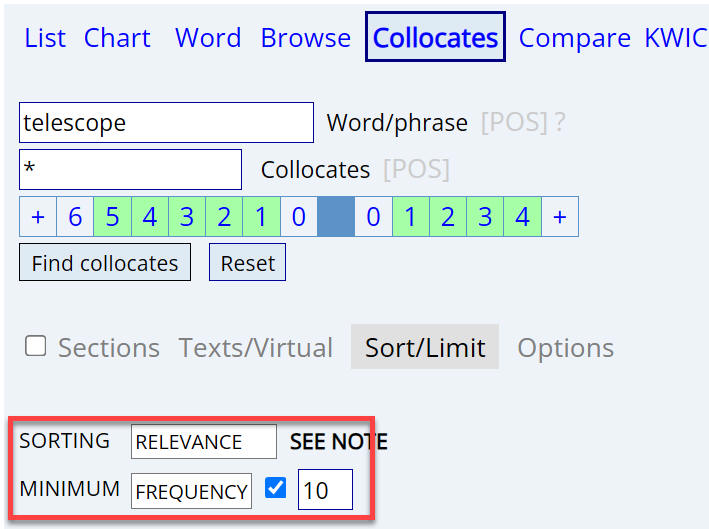 |
If you want to focus even more on words
that are highly correlated with a given word (but again, missing out on
more basic words, like space with telescope), then sort
by Relevance (which means Mutual Information), as is shown in the image to
the left.
Mutual Information is basically a measure of how much we can
predict the occurrence of a collocate, given a certain node word. For
example, given the word wreak, there is a high probability of
finding havoc nearby. But again, if you do use Relevance /
Mutual Information, it is important that you set the minimum frequency.
The corpus will suggest a value (like 3 or 5 or 10, or for very large
corpora like
iWeb or
NOW maybe even 20 or
50), and it's probably good to at least start with that value. Very
briefly, the reason is that a very low frequency word might occur only a
few times in the entire corpus. And almost by chance, in those handful
of occurrences, it happens to be near your node word. For example,
see
strange collocates of sunset like
out-house, Uluwatu, or 38-F, which have a frequency of just 1
or 2 tokens and which have a high Mutual Information value, but which
really don't tell us anything about the meaning of sunset). So
the Mutual Information score will think that the two words are high
correlated to each other, when they really aren't. If you are sorting by
Relevance (Mutual Information), it is good to have a frequency filter,
to reduce the chance of these "random co-occurrences". |
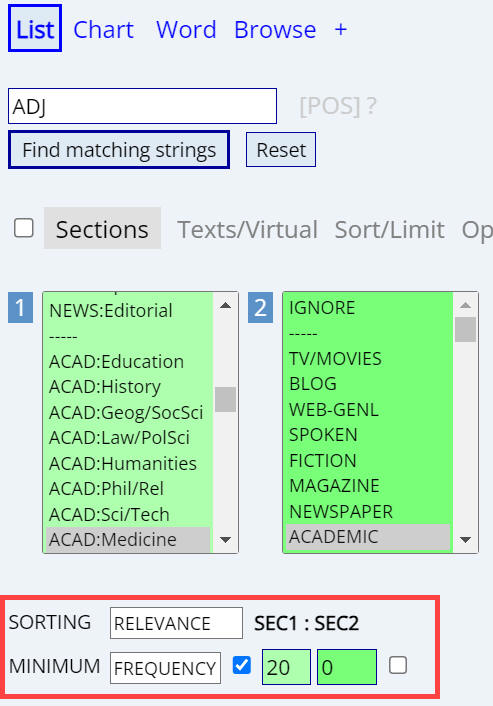
Comparing the results in two sections
Whenever you compare something in two sections of a corpus -- such as
Academic-Medicine and Academic in COCA, or the 1800s and 1900s in COHA, or US/CA
and UK/IE in GloWbE, the corpus will automatically set Sorting to Relevance, and
it will automatically set a Minimum Frequency level for the first section.
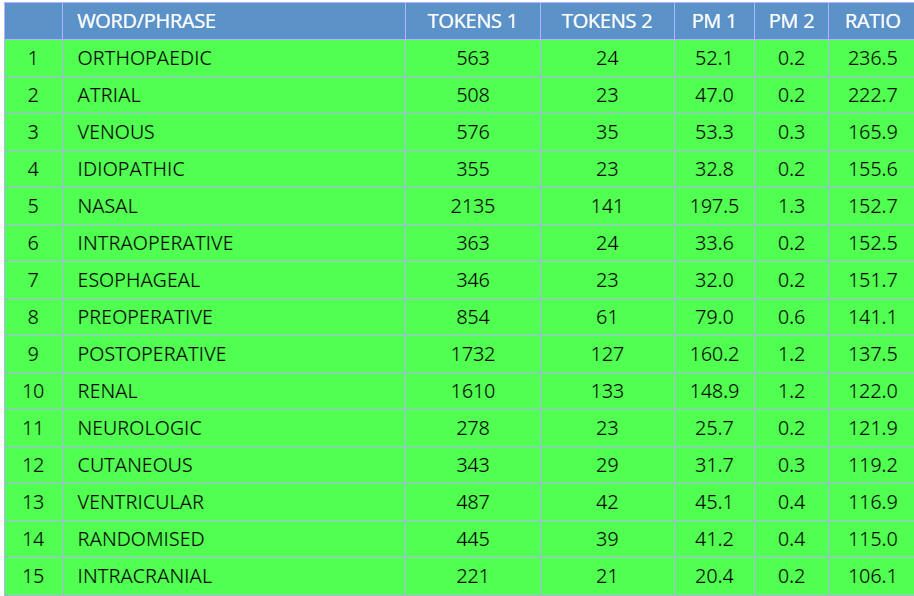
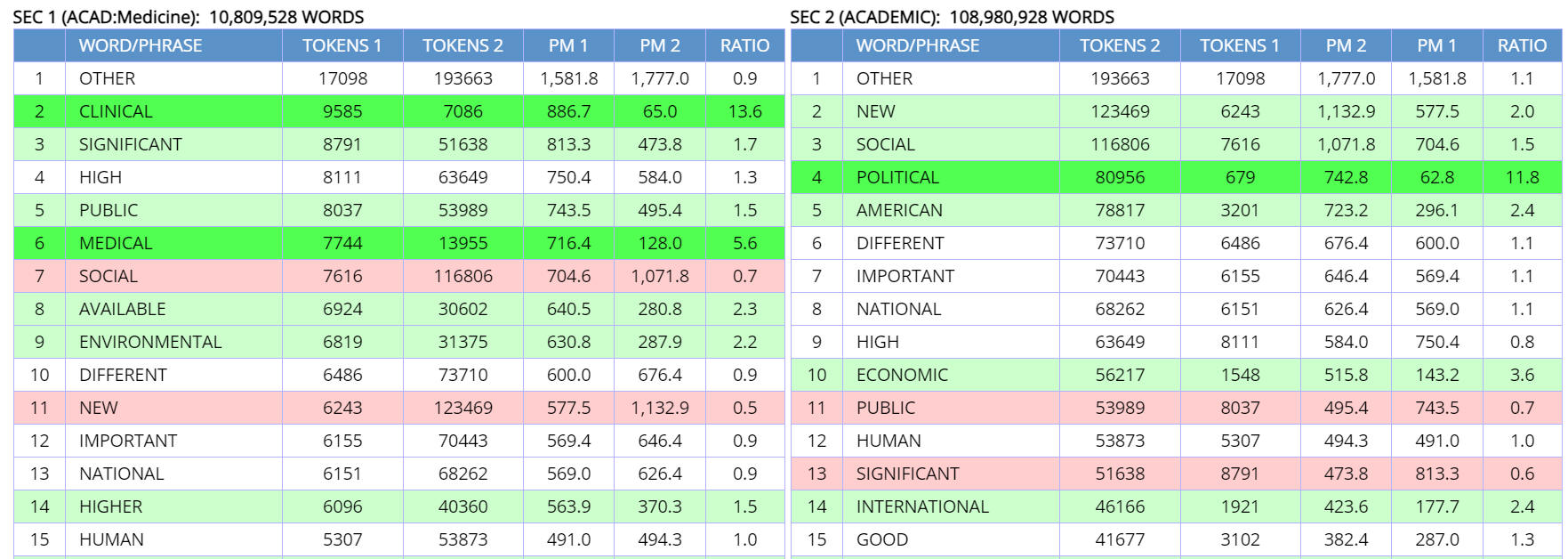
For example, suppose we are comparing ADJ in different sections in COCA. Once
we select Academic-Medicine for Section 1 and Academic (general) for Section 2
in COCA, the corpus sets Sorting and Frequency as is seen in
(1) below.
(In the
following examples, you may need to scroll down the entries in Section 1 to see
where Academic-Medicine is selected). We could lower the Minimum Frequency to
see even more specific words. Or we could increase the Minimum Frequency to see
words that -- while still more common in Section 1 -- are less specific to that
section. For example, if we increase it to 1000 (i.e. 1000 tokens of the ADJ in
Section 1), we would see the results in
(2).
Another way to make sure that the words in Section 1 are not too specific
to that section is to require that the words or phrases or collocates occur
with at least a certain frequency in Section 2. For example, in (1)
above,
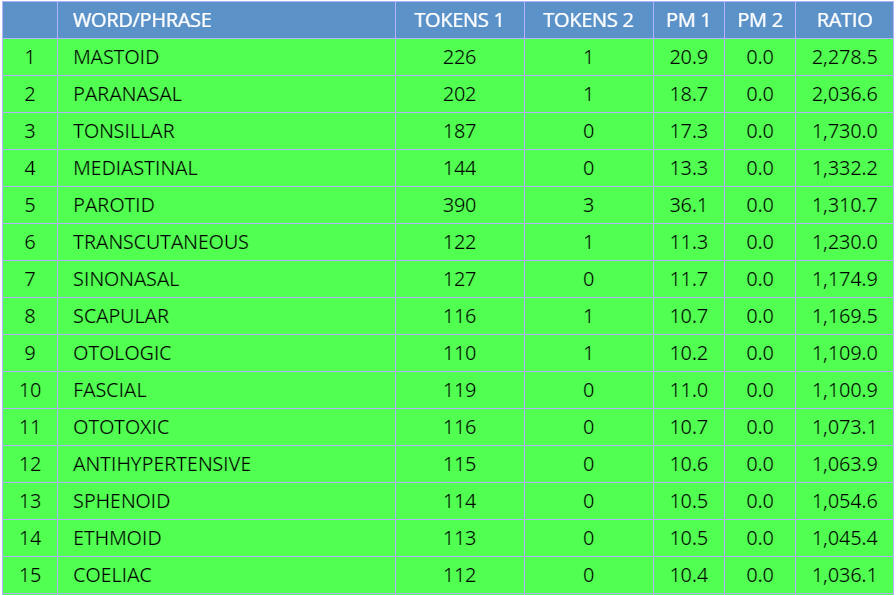
the adjective doesn't have to occur at all in Section 2. And as a result, we
have words like tonsillar,
mediastinal, sinonasal, ototoxic that don't occur at all in
Section 2 (which is the rest of Academic, not including Academic-Medicine). But suppose
we require the adjective to occur at least 20 times outside of the Medicine
sub-genre, as shown in
(3). (Note
that if it
occurred 20 times outside of Medicine, it would still be much less common
than the 30 tokens in Academic-Medicine, since there are 110 million words
of data in Academic outside of Medicine, and "only" 10 million words in
Medicine). And so in this case, notice that the list is much "cleaner" and
less "Medicine-only" in terms of its vocabulary.
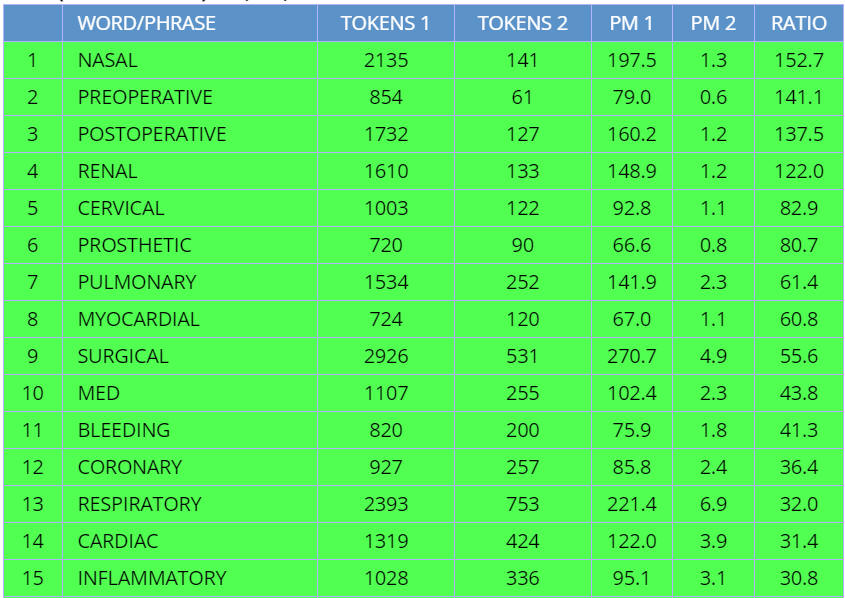
Finally, we could decide not to order the frequency by the relative
frequency in Section 1 vs Section 2, but rather just show the most frequent ADJ in each
section, regardless of how many times it occurs in the other one, as shown in
(4).
Again, we can compare almost anything between two sections of the corpus --
individual words (as in these cases with ADJ in COCA), phrases (e.g.
ADJ + women in COHA: 1870s-1920s vs 1970s-2000s),
collocates (e.g.
words
near scheme in GloWbE: US vs GB), or even synonyms (e.g.
=strong
in COCA: fiction vs academic) or words that you've created in a
customized word list. The
important point is that you have complete control over how specific the words or
phrases or collocates are in the different sections of the corpus.
Comparing two words
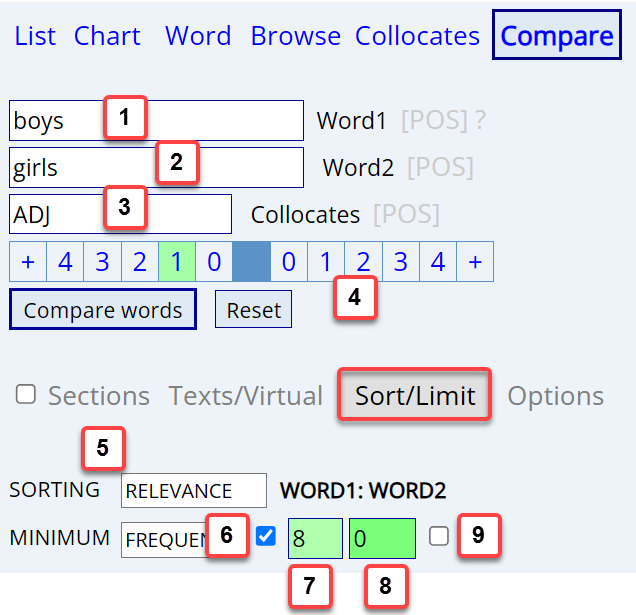 |
You can compare the collocates (and
therefore the meaning and usage) of two words, such as nouns near
utter
and complete,
or
warm
/ hot, or small
/ little,
or the adjectives near boys
and girls or
Democrats
and Republicans, or the objects of
destroy / ruin or
sanction / approve. See the
Compare Words page for basics on
how to do one of these searches. This page deals more with how to set
the Sorting and Limits options.
[5] By default, the
search will sort by [Relevance], and it will show the collocates that
are more frequent with one word than with another. But if you want to
see which words are the most frequent with each of the two words
(regardless of the frequency with the other word), then choose
[Frequency]. For example, destroy vs ruin:
relevance,
frequency (notice people, family, economy high on the list
for both verbs)
[6,7] Minimum frequency
for the collocates of the first word
[1]. This can help limit
the collocates to just those that really are frequent. For example,
profound vs deep:
frequency of at least 20,
no
limits (notice possibly less useful collocates like uses,
arrogance, works). The frequency often depends on the overall size
of the corpus, such as perhaps 50 in a large corpus like
iWeb to maybe 10 in
COCA, and perhaps
just 3 or 4 in a small corpus like the
BNC. If you do
specify a minimum frequency [7],
make sure that you also check the box
[6].
[8,9] Minimum frequency
for the collocates of the second word
[2]. Again, if you do
specify a number, then make sure you also check the box
[9]. Whether or not you
input a value for [8]
(and select [9]) is often
an important part of the setting up the search. For example, look at ADJ
before boys vs girls:
no
limits on the frequency of the collocates of the second word,
lower
limit of 2 for the collocates of the second word. In the
first
case, there are a number of words that can only appear with either
boys or girls, perhaps because it is the name of a series
of books (Hardy Boys) or a girl band (Indigo Girls), or it
is an idiomatic phrase (whipping boys), or it can only apply to
one of the two in the real world (pregnant girls). In the second
case (limit of 2), all of those entries disappear, because there is no
book series called the Hardy Girls, no boy band
called Indigo Boys, no idiomatic phrase
whipping girls, and there are few if any
pregnant boys in the real world. On the other hand, in
cases like
bizarre / strange,
destroy / ruin, or
sanction / approve, it is not as important to
indicate the minimum frequency for the second word. |
Other options for sorting
You can also sort the entries alphabetically, although (to be honest)
it's not entirely clear why you would want to. For example, we could search for
tr* truck,
and we would see results like the following. You will probably also want to have
a minimum frequency (we have selected 5 in this case), since (because we aren't
sorting my something really meaningful, like frequency or relevance) there will
probably be a lot of low frequency (1-2 token) words or strings.
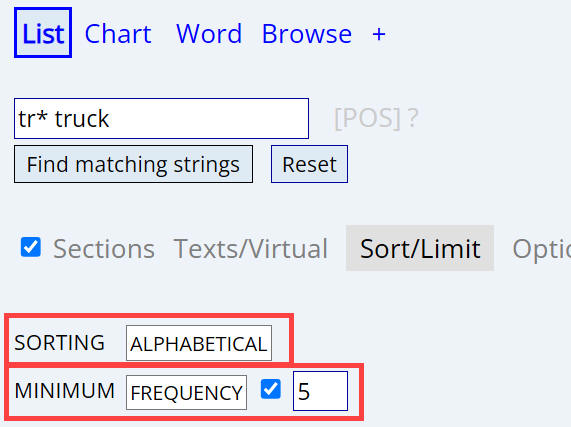 |
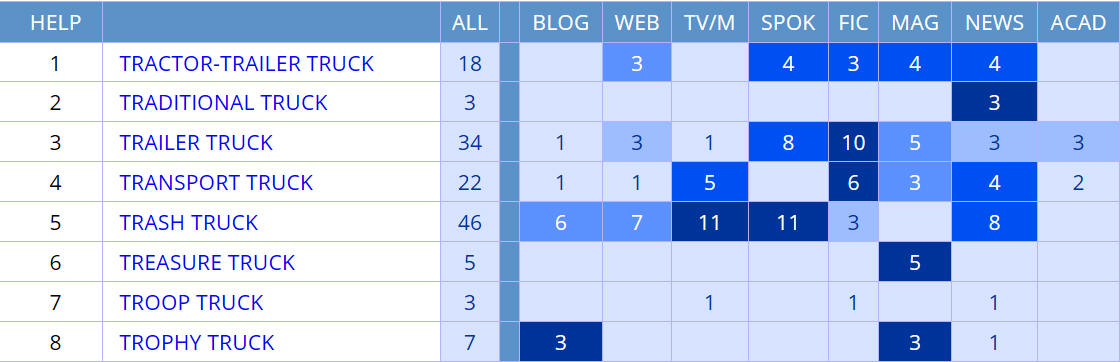 |
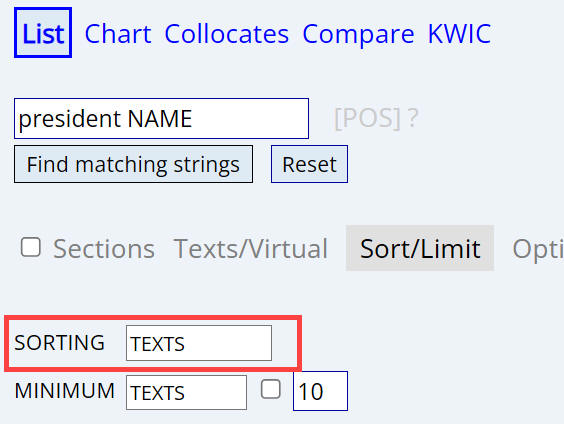
One other option for sorting, which does make sense, is to sort by the
number of texts that have the word or phrase or collocate. You might want to
use this option when you suspect that some of the entries are found in only a
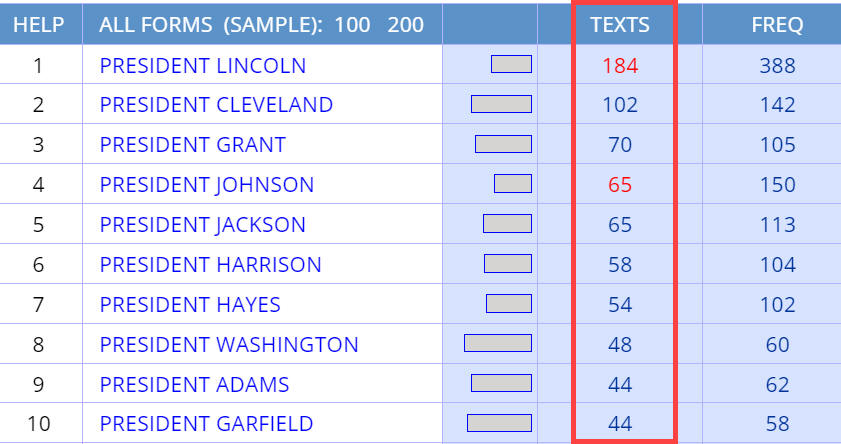
small number of texts. For example, a search for
President
NAME in COHA for the 1820s-1890s gives the results shown below
(note that we have also set OPTIONS / SHOW #
TEXTS to [YES]. Notice that there are some entries (like President
Manning) that occur in only a handful of texts (3 texts, in the case of
President Manning). We might not want our results to be skewed by words
or phrases that occur in just a few texts.

One option is to set a minimum number of texts (for example, the word or
phrase must
occur in at least 10 texts). Or we might sort the results by the number of
texts that they occur in. In other words, if it really is a frequent word or
phrase, then lots of texts should have it. When we
sort by the
number of different texts that have the matching strings for President NAME,
the results seem to be quite good (for texts from the 1800s, of course):
|