Word / phrase searches (search
form,
corpora used,
corrections,
+/- sections,
compare to
Chart,
Collocates searches)
Word / phrase searches (search
form,
corpora used,
corrections,
+/- sections,
compare to
Chart,
Collocates searches)
 |
Note: click on any link
on this page to see the corpus data, and then
click on the "BACK" image (see left) at the top of the page to come back to
this page. Or right click on the link and then "Open link in new tab" (in
Chrome; similar in other browsers), and then close that tab after
viewing the corpus data. |
In most cases, the examples in
these linked pages comes from the Corpus of Contemporary American English
( COCA), since it is the most widely used of the corpora from English-Corpora.org
(and probably the most widely-used online corpus anywhere).
A number of examples also come from
COHA (historical),
GloWbE (dialects), and
NOW (very large and recent). But all of the information in these help files should
be applicable to any of the 17 corpora at English-Corpora.org.
(close)
Please note that these pages were recently released (in September
2024), and there are probably still some errors, since English-Corpora.org has
been created and is run by just one person. If you find anything that needs to be corrected, please
email us. Thanks.
(close)
Basic syntax: see also "flex"
(variable length) queries
|
Type |
Examples |
Results |
Explanation / notes |
|
Single word |
mysterious
skew |
mysterious, skew |
Remember that if you want to see the frequency by
section (genre, historical period, dialect, etc), the better option is
probably a
Chart search |
|
Exact phrase |
make up
. In
particular , |
make up, on the other hand |
Some words that are a single "word" in written English are considered
two "words" by
the program that tagged the corpus. A few examples:
ca n't,
they 'll, Mary 's. In addition, punctuation is considered to be a
separate word, such as VERB out . or ADJ ! Finally
(unlike with online search engines like Google), there is no need to put
quotes before and after an exact phrase:
"San Francisco",
"good idea". |
|
Any word |
more * than
*
bit |
more important than, more money than
a bit, tiny bit |
Each asterisk matches one word. So put * * into would show four
word strings, with put followed by exactly two words, and then
into. If you want a variable number of words (for example, 1 to 3
words), see the powerful, new
"flex"
(variable length) queries. |
|
Wildcard |
*icity
*break*
b?t?er
??????*ism |
electricity, multiplicity
break, outbreak, unbreakable
better, butter, butler
criticism, multiculturalism |
? matches exactly one letter, and * matches any number of letters
(including no letters). You can combine these two symbols to find words
between N1 and N2 characters long. For example, ??????*ism would find
words with at least nine letters (the six ? plus ism), but
it wouldn't find tourism or realism (there are not at least six
letters before ism) |
|
Alternant |
fast|slow
fast|slow
rate|progress |
fast, slow
slow rate, fast rate, slow progress |
You can use either "|" or "/" -- they will yield the same results |
|
NOT |
pretty
-NOUN |
pretty good, pretty tall |
Compare pretty
NOUN |
|
Lemma (forms) |
DECIDE
CURVE_n |
decide, decides, decided, deciding
curve, curves |
(See below) |
|
Part of speech |
rough NOUN
VERB
money |
rough time, rough terrain, rough idea
raise money, saving money |
(See below) |
|
Synonyms |
=beautiful
=strong
ARGUMENT |
beautiful, lovely, attractive
compelling argument, effective arguments |
(See below) |
|
Customized word lists |
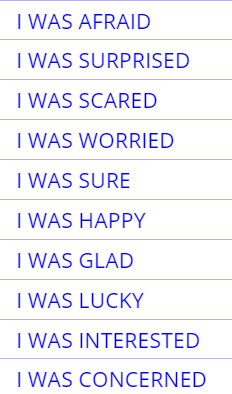
I was
@emotion
@colors
@CLOTHES |
is happy, was sad, been worried
white shirt, blue pants, pink blouse |
(See below) |
Lemmas (forms of words)
If you capitalize an entire word, it will find all forms of that
word. For example, DECIDE would
find all forms of decide (decide, decides, decided, deciding), whereas decide would
just find the single form decide. Note than CURVE_n wouldn't
yield curved or curving, since we have limited it just to nouns by
appending _n.
Also, note that these are traditional lemmas, which are similar to headwords in
a dictionary. In the same way that happy, unhappy, and happiness
are all different entries in a dictionary, HAPPY would not yield
unhappy or happiness -- those are different lemmas. In other
words, this is different than the "word families" approach developed by Paul
Nation, where those three words are part of one "word family".
Synonyms
You can search by all of the synonyms of a given word, which
provides powerful "semantically-based" searches of the corpus. For example, you
can find the synonyms of beautiful, nonsense,
or clean
(v).
Of course you can use the synonyms as part of phrases as well.
For example, =CLEAN
the NOUN, =clever
=man, or =strong
ARGUMENT. As the last example shows, synonyms can be very
useful when you are a non-native speaker, and you want to know which related
words are used in a particular context.
As =clean
* NOUN shows, not every token will actually be a synonym of a
given word in every case. For example, scour may be a synonym of clean in scour
the sink, but not in scour the library for good books.
Note the it is often useful to limit the synonyms to those with a
particular part of speech, as in =clean_v.
It is often also useful to find all forms of the synonyms, by capitalizing the
word: =CLEAN.
And of course you can combine these as well, for example all
forms of all synonyms of clean as a verb (=CLEAN_v).
|
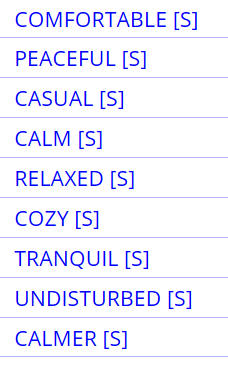
Finally, note that you can click on the [S] in
the results to
find synonyms for each word in the results set. This allows you to
follow a "synonym chain" from one word to another to another. And of
course you can see the frequency of each word, and see it in context as
well. |
 |



 |
Customized word lists (detailed
help:
PDF,
video)
|
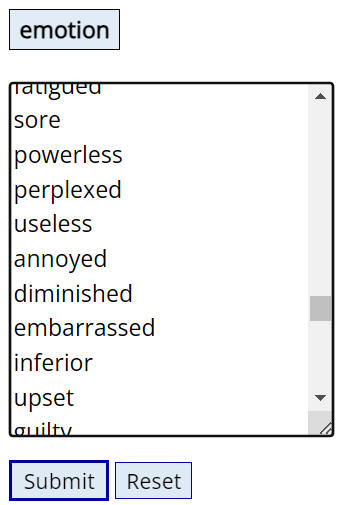
"User lists" or "customized lists" are word lists that you create
-- related to a certain topic (e.g. sports, clothing, or emotions), words that
are grammatically related (e.g. a certain subset of adverbs or pronouns), or any
other list that you might want. After you've created a list, you
can then re-use it in queries at any time in the future -- they remain stored in
the database on the server.
You can also view the lists that you have created, and modify the wordlist (add
or delete words), or delete a list entirely.
To include the words in a customized wordlist in your search, the syntax is:
@listName (for example, @foods or @emotion)
|
 |
 |
 |
|
You can also use the list as part of a phrase:
I was
@emotion,
@colors @CLOTHES
(note the capitalized CLOTHES, to find plural forms of these words as well)
|
Part of speech
You can use parts of speech as part of your query. For example, ADJ
eyes would find a two word string, composed of an
adjective followed by the word eyes. Some other examples are: rough
NOUN, Bill
NAME, VERB
* money, MOVE
ADV, NUM
ways, LET
PRON VERB.
You can type the part of speech tags directly into the search form as part of a
search. (Click here for a
full list of these part of speech tags.) You can also insert part of speech
tags is by selecting them from the drop-down list:
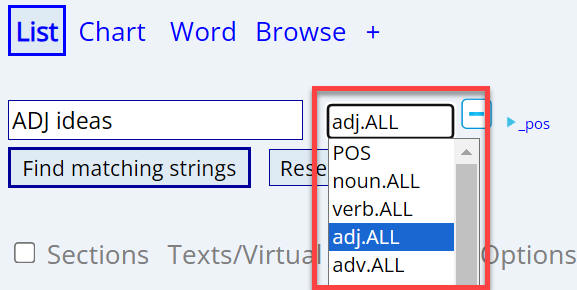
There are different ways of specifying the part of speech
-- all of which work equally as well. For example, all of the following would
find the same strings: ADJ
eyes, J
eyes, _j
eyes,
[j*]
eyes
|
1.
Word |
2. Abbreviation |
3. CQP-like |
4. Older syntax |
Explanation |
Example |
|
NOUN |
N |
_nn |
[nn*] |
Common noun |
sun, love |
|
NAME |
NP |
_np |
[np*] |
Proper noun |
John, Chicago |
|
NOUN+ |
N+ |
_n |
[n*] |
Common and proper noun |
sun, Sonny |
|
VERB |
V |
_vv |
[vv*] |
Lexical verb (no do, be, have) |
decide, jumped |
|
VERB+ |
V+ |
_v |
[v*] |
All verbs (including do, be, have) |
decide, has, is |
|
ADJ |
J |
_j |
[j*] |
Adjective |
nice, clean |
|
ADV |
R |
_r |
[r*] |
Adverb |
soon, quickly |
|
PRON |
|
_p |
[p*] |
Pronoun |
she, everyone |
|
PREP |
|
_i |
[i*] |
Preposition |
from, on |
|
ART |
|
_a |
[a*] |
Article |
the, his |
|
DET |
|
_d |
[d*] |
Determiner |
these, all |
|
CONJ |
|
_c |
[c*] |
Conjunction |
that, and, or |
|
NEG |
|
_x |
[x*] |
Negation |
not, n't |
|
NUM |
|
_m |
[m*] |
Number |
five, 5 |
|
POSS |
|
_ap |
[ap*] |
Possessive |
my, her, their |
|
All other parts of speech: use Type
3 or Type 4, e.g.
[nn2*], _nn2, [cst*], _cst |
If you are using Type 3 or Type 4 above, you can use wildcards
for the part of speech tag. For example, [nn2*] =
plural nouns, [n*] =
all nouns, [*n*] =
nouns (including ambiguous noun/adj tags), etc. If you are using Type 1 or Type
2, it needs to be upper case: short
NOUN (or short N).
You can also add a part of speech tag to the end of any word, but
you need to use either Type 3 or Type 4 above. For example, end would
find end with any part of speech, but end.[n*] or end_n would
limit it to end as a noun, and end.[v*] or end_v would
limit it to end as a verb. (Click on the word in the results to
see the KWIC (concordance) lines, to verify that they are (mostly) nouns or
verbs; there will always be some entries that are mistagged.) Make sure that you separate the word and the
part of speech with an underscore (Type 3) (end_v), or a period / full stop and bracket (Type
4) (end.[v*]), and remember that in either case, there is no space between the
word and the part of speech tag. Also remember also that you can combine these
with lemma searches to find all forms of a word with a given part of speech,
e.g. END_v or END.[v*].
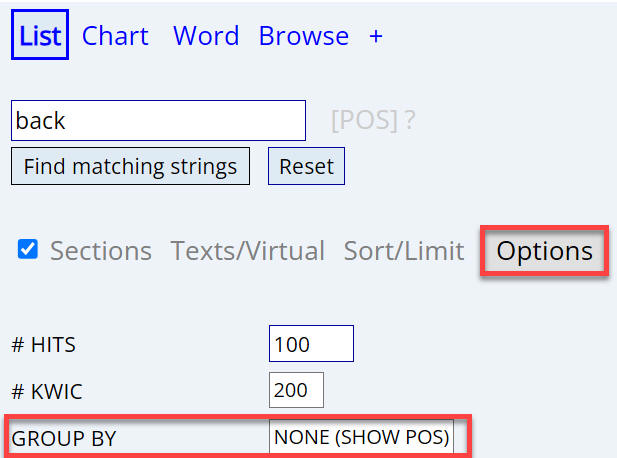
 Hint: if you don't know what the part of speech tag is for a given word
(or the words in a phrase), just select [OPTIONS] and then [GROUP BY] = [NONE]
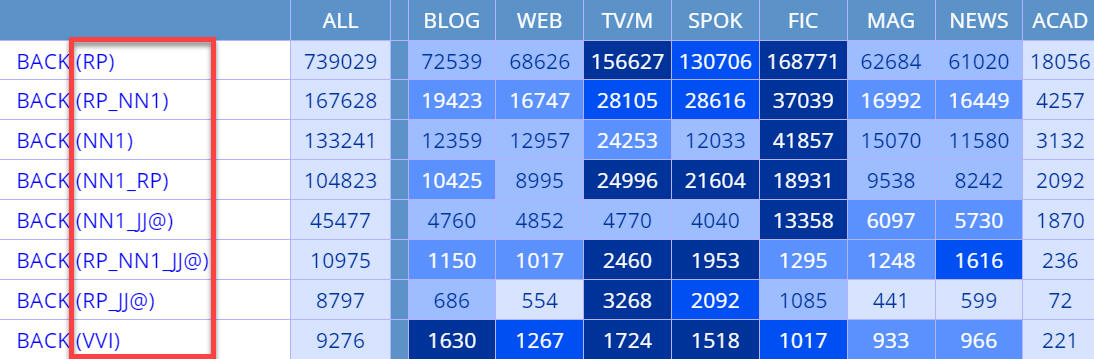
(SHOW POS). For example, see the PoS tags for light, back, everyone,
or in
light of . (More information) Hint: if you don't know what the part of speech tag is for a given word
(or the words in a phrase), just select [OPTIONS] and then [GROUP BY] = [NONE]
(SHOW POS). For example, see the PoS tags for light, back, everyone,
or in
light of . (More information) |
 |
Combining words
Many of the examples shown above are for individual words. But
of course you can combine the different types of searches to create fairly complex
phrases. For example:
|
Example |
Explanation |
|
fast|rapid|quick NOUN |
Any of these three words followed by a noun |
|
GET him|her to VERB |
Any form of get + him or her + to +
verb |
|
CONJ
VERB it out .|, |
Notice that punctuation can be used like any "word"; just
make sure that it is separated from words by a space. |
|
BEAT_v * NOUN+ |
Any form of beat (as a verb) followed by any word,
and then a noun |
|
*ly_r =gorgeous NOUN |
Adverb (_r( ending in ly, followed by a synonym of gorgeous, followed by a noun. |
|
PUT
on POSS @CLOTHES_n |
Any form of PUT + on + a possessive + any
form of any word in the "clothes" list, used as a noun. |
|