KWIC (concordance) searches (search
form,
corpora used,
corrections,
+/- sections
compare to
Word / phrase and
collocates
searches)
KWIC (concordance) searches (search
form,
corpora used,
corrections,
+/- sections
compare to
Word / phrase and
collocates
searches)
 |
Note: click on any link
on this page to see the corpus data, and then
click on the "BACK" image (see left) at the top of the page to come back to
this page. Or right click on the link and then "Open link in new tab" (in
Chrome; similar in other browsers), and then close that tab after
viewing the corpus data. |
In most cases, the examples in
these linked pages comes from the Corpus of Contemporary American English
( COCA), since it is the most widely used of the corpora from English-Corpora.org
(and probably the most widely-used online corpus anywhere).
A number of examples also come from
COHA (historical),
GloWbE (dialects), and
NOW (very large and recent). But all of the information in these help files should
be applicable to any of the 17 corpora at English-Corpora.org.
(close)
Please note that these pages were recently released (in September
2024), and there are probably still some errors, since English-Corpora.org has
been created and is run by just one person. If you find anything that needs to be corrected, please
email us. Thanks.
(close)
Keyword in Context
(KWIC, and also known as concordance) searches allow you to see the patterns
in which a word occurs. Word/phrase searches allow you to search for
specific strings of words. Collocates searches allow you to see the nearby
words in a "cloud of words" around a given word. But KWIC searches allow you
to see the patterns in which a word occurs, in ways that can't be done with
the other two types of searches.
Well, this is mostly
true. Let's take the example of fathom, which means "to understand".
Suppose we want to know the patterns in which this word occurs. We could
search for
* *
fathom to see the two word strings that occur to the left of
fathom, and we would see that they are negative, or that they at least
mention that it is hard or difficult to fathom: 
But should we search one word to the left, or two words, or three? Should we
sort by words to the left or right of the "node word" (in this case
fathom) to find interesting patterns? And how could we see phrases
that occur in the context to the right or the left? This is exactly what
KWIC searches do the best.
For example, look at the following partial entries from the
KWIC lines for
fathom. (Note that
the saved search linked to above will replicate the search, but not the
exact KWIC lines. You will see similar KWIC lines, but probably not the
exact same ones as in these images.) We can easily scan through these lines and
see that the preceding words -- whether one, two, three words (or more) --
all express the "negative / questioning" sense accompanies the word
fathom. (This is a good example of
semantic prosody.)

And look at these KWIC lines for
naked eye.
We can quickly scan through the entries to find repeated phrases, like
visible/invisible to the naked eye or see X with the naked eye.
It would be much more difficult to find patterns like this by just looking
for exact four or five words strings, or with collocates (which just find
single words somewhere nearby another word).


Consider these lines with
gone the
way of the, which refers to things that have gone extinct or
disappeared (and this is just a small portion of the results). We can
quickly scan through the entries and see phrases like dinosaurs, dodo
(birds), rotary phones, side rule (calculator), and
typewriters. Again, it would be difficult to find phrases like this with
just phrase searches like gone the
way of the * * or by using collocates (which will just find
single words, not phrases).


Finally, consider the phrase
END up.
Because the words (three words to the left and three words to the right of
our search word) are color coded, we can quickly scan through the entries to
see what parts of speech occur near our search word (in corpus linguistics,
this is referred to as colligation). We see that with end up,
there are many -ing forms of verbs (in pink), a few adjectives (in green),
and prepositional phrases with the word with (in yellow). Patterns of
co-occurring words and phrases and parts of speech almost "jump out" at us
with these KWIC searches.

How to set up the search
|
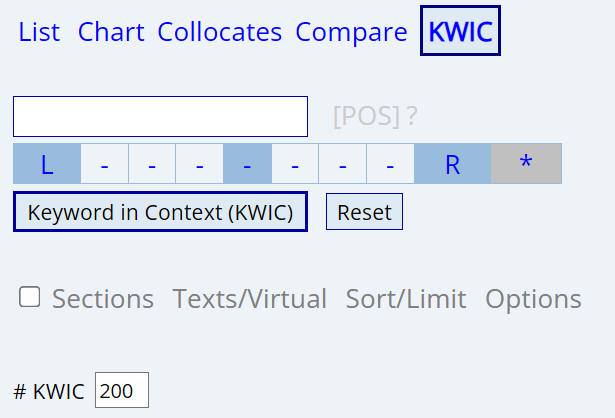 |
Select the words that you want to sort
with. Select L
for 1, 2, and 3 words to the left (as with fathom and
naked eye above). In other words, it first sorts the words by 1
"slot" to the left, and then (in cases of a "tie") by the second
word to the left, and then the third word to the left. Select
R for 1, 2, and 3
words to the right (as with go the way of the and END up
above). You could also, for example, sort by one word to the left,
then one and two words to the right, such as with
matter (n) or
point (n), or any other combination. Click
* to clear the entries and start over.
You can also
select the number of entries -- 100, 200, 500, or 1000 entries |
|
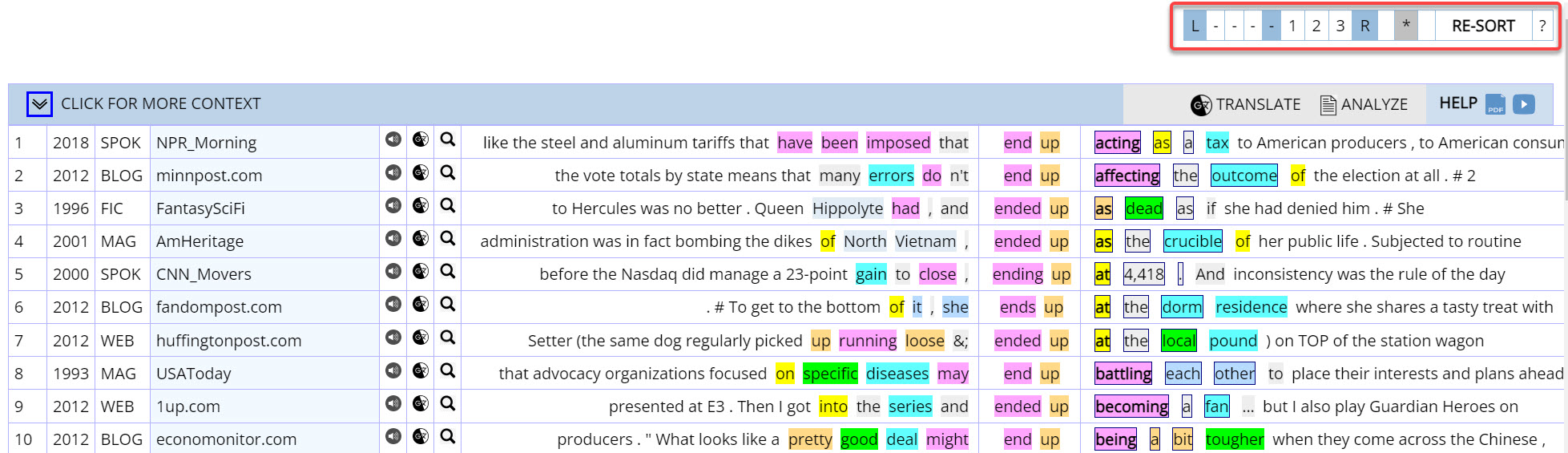 |
After you have done the search, you
can also re-sort the entries from within the KWIC entries page, by
clicking on the table at the top right (shown here in red). As
before, you can sort by L
(left), R
(right), or manually select any combination of these. And as before,
click on * to clear
the entries and start over. You can also see a key to the color
codes for part of speech, copied here:
 |
As with word/phrase and collocates searches, you can also limit the KWIC
search by section in the corpus. For example, the following are entries for END
up in COHA (the Corpus of Historical American English) in the
1820s-1890s
and then in the
1980s-2010s.
Notice how there are no cases of VERB-ing in the 1800s (i.e. no words in pink
after END up), but those are the majority of the entries in the
1980s-2010s.


|